27.100万QPS短链系统如何设计?
2025/12/19大约 6 分钟
27.100万QPS短链系统如何设计?
前言
凌晨两点,监控大屏突然飙红——短链服务QPS突破80万! 数据库连接池告急,Redis集群响应延迟突破500ms。
这不是演习,而是某电商平台大促的真实场景。
当每秒百万级请求涌向你的短链服务,你该如何设计系统?
今天这篇文章跟大家一起聊聊100万QPS短链系统要如何设计?
希望对你会有所帮助。
1 短链系统的核心挑战
首先我们一起看看设计一个高并发的短链系统,会遇到哪些核心的挑战。
如下图所示:
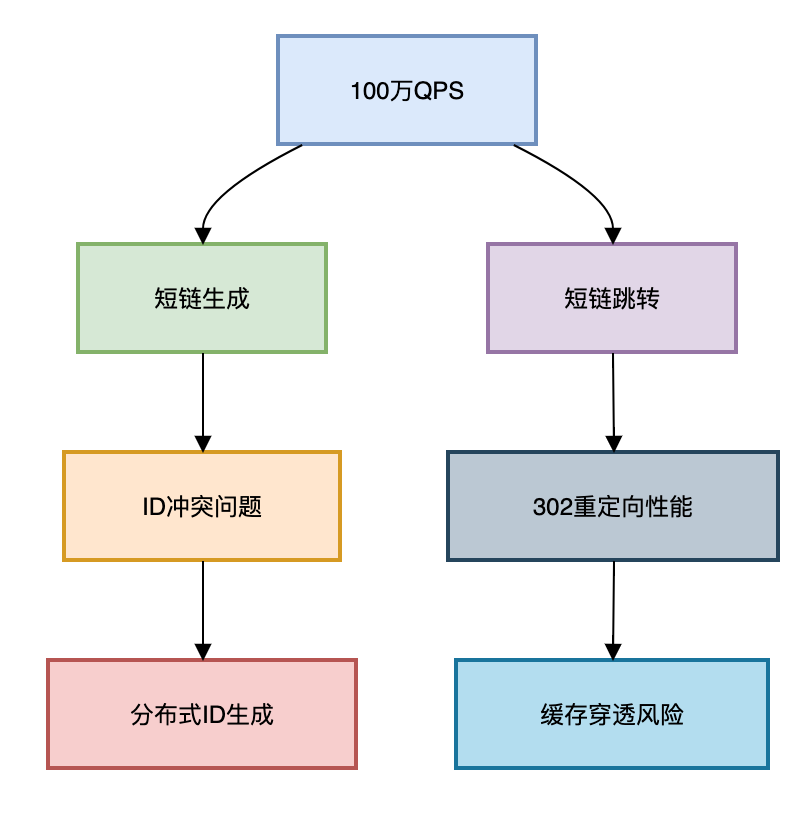
百万QPS下的三大生死关:
- ID生成瓶颈:传统数据库自增ID撑不住百万并发
- 跳转性能黑洞:302重定向的TCP连接成本
- 缓存雪崩风险:热点短链瞬间击穿Redis
2 短链生成
2.1 发号器的设计
发号器是短链系统的发动机。
方案对比:
| 方案 | 吞吐量 | 缺点 | 适用场景 |
|---|---|---|---|
| UUID | 5万/s | 长度长,无法排序 | 小型系统 |
| Redis自增ID | 8万/s | 依赖缓存持久化 | 中型系统 |
| Snowflake | 12万/s | 时钟回拨问题 | 中大型系统 |
| 分段发号 | 50万/s | 需要预分配 | 超大型系统 |
分段发号器实现(Java版):
public class SegmentIDGen {
private final AtomicLong currentId = new AtomicLong(0);
private volatile long maxId;
private final ExecutorService loader = Executors.newSingleThreadExecutor();
public void init() {
loadSegment();
loader.submit(this::daemonLoad);
}
private void loadSegment() {
// 从DB获取号段:SELECT max_id FROM alloc WHERE biz_tag='short_url'
this.maxId = dbMaxId + 10000; // 每次取1万个号
currentId.set(dbMaxId);
}
private void daemonLoad() {
while (currentId.get() > maxId * 0.8) {
loadSegment(); // 号段使用80%时异步加载
}
}
public long nextId() {
if (currentId.get() >= maxId) throw new BusyException();
return currentId.incrementAndGet();
}
}关键优化:
- 双Buffer异步加载(避免加载阻塞)
- 监控号段使用率(动态调整步长)
- 多实例分段隔离(biz_tag区分业务)
2.2 短链映射算法
短码映射将长ID转换成62进制的字符串。
转换原理:
2000000000 = 2×62^4 + 17×62^3 + 35×62^2 + 10×62 + 8
= "Cdz9a"原始ID: 2000000000,转换为62进制的值为Cdz9a。
// Base62编码(0-9a-zA-Z)
public class Base62Encoder {
private static final String BASE62 =
"0123456789ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz";
public static String encode(long id) {
StringBuilder sb = new StringBuilder();
while (id > 0) {
sb.append(BASE62.charAt((int)(id % 62)));
id /= 62;
}
return sb.reverse().toString();
}
// 测试:生成8位短码
public static void main(String[] args) {
long id = 1_000_000_000L;
System.out.println(encode(id)); // 输出:BFp3qQ
}
}编码优势:
- 6位短码可表示 62^6 ≈ 568亿种组合
- 8位短码可表示 62^8 ≈ 218万亿种组合
- 无意义字符串避免被猜测
3 存储架构
3.1 数据存储模型设计
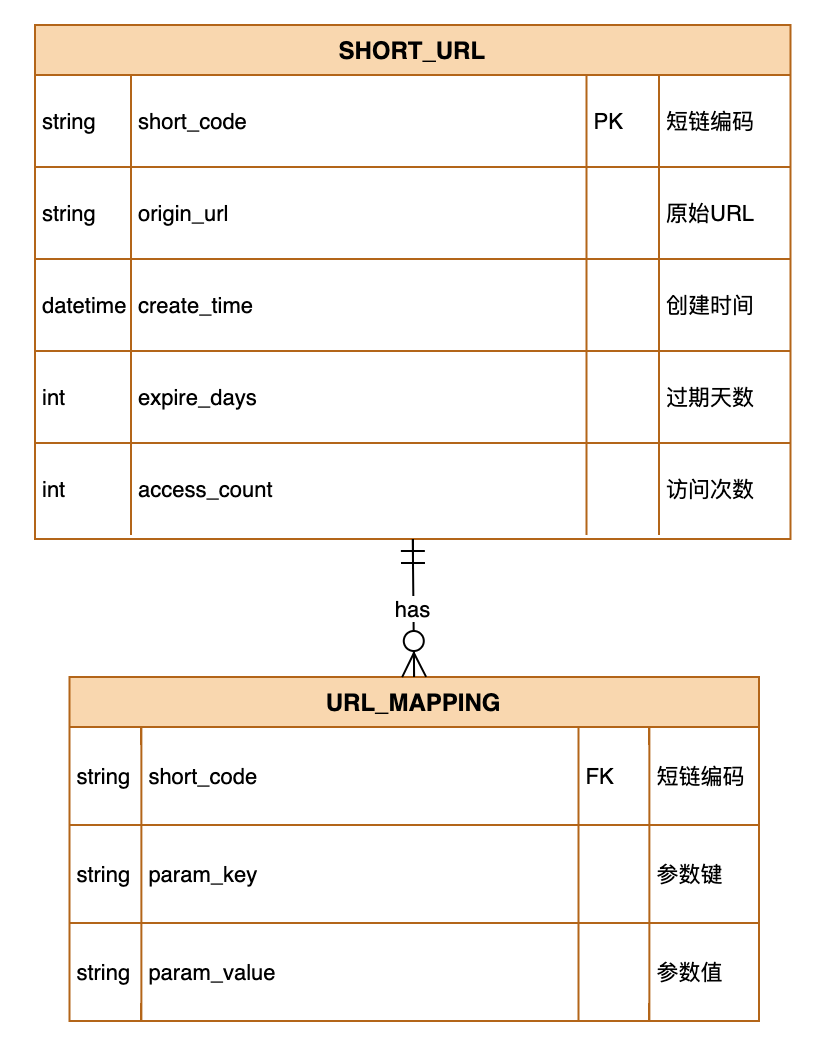
3.2 缓存层级设计
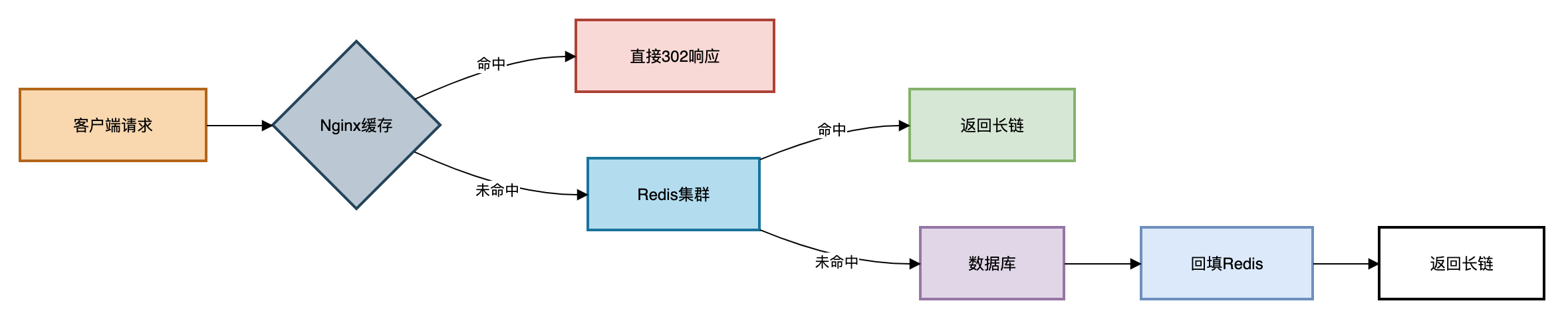
3.3 缓存击穿解决方案
// Redis缓存击穿防护
public String getLongUrl(String shortCode) {
// 1. 布隆过滤器预检
if (!bloomFilter.mightContain(shortCode)) {
return null;
}
// 2. 查Redis
String cacheKey = "url:" + shortCode;
String longUrl = redis.get(cacheKey);
if (longUrl != null) {
return longUrl;
}
// 3. 获取分布式锁
String lockKey = "lock:" + shortCode;
if (redis.setnx(lockKey, "1", 10)) { // 10秒超时
try {
// 4. 二次检查缓存
longUrl = redis.get(cacheKey);
if (longUrl != null) return longUrl;
// 5. 查数据库
longUrl = db.queryLongUrl(shortCode);
if (longUrl != null) {
// 6. 回填Redis
redis.setex(cacheKey, 3600, longUrl);
}
return longUrl;
} finally {
redis.del(lockKey);
}
} else {
// 7. 等待重试
Thread.sleep(50);
return getLongUrl(shortCode);
}
}防护要点:
- 布隆过滤器拦截非法短码
- 分布式锁防止缓存击穿
- 双重检查减少DB压力
- 指数退避重试策略
4 跳转优化
最近建一些几十个工作内推群,各大城市都有,群里目前已经收集了很多内推岗位,大厂、中厂、小厂、外包都有。 欢迎HR、开发、测试、运维和产品加入。
扫描下方微信,备注:网站+所在城市,即可拉你进工作内推群。

4.1 Nginx层直接跳转
server {
listen 80;
server_name s.domain.com;
location ~ ^/([a-zA-Z0-9]{6,8})$ {
set $short_code $1;
# 查询Redis
redis_pass redis_cluster;
redis_query GET url:$short_code;
# 命中则直接302跳转
if ($redis_value != "") {
add_header Cache-Control "private, max-age=86400";
return 302 $redis_value;
}
# 未命中转发到后端
proxy_pass http://backend;
}
}性能收益:
- 跳转延迟从100ms降至5ms
- 节省后端服务器资源
- 支持百万级并发连接
4.2 连接池优化
连接池优化可以用Netty实现:
// Netty HTTP连接池配置
public class HttpConnectionPool {
private final EventLoopGroup group = new NioEventLoopGroup();
private final Bootstrap bootstrap = new Bootstrap();
public HttpConnectionPool() {
bootstrap.group(group)
.channel(NioSocketChannel.class)
.option(ChannelOption.SO_KEEPALIVE, true)
.handler(new HttpClientInitializer());
}
public Channel getChannel(String host, int port) throws InterruptedException {
return bootstrap.connect(host, port).sync().channel();
}
// 使用示例
public void redirect(ChannelHandlerContext ctx, String longUrl) {
Channel channel = getChannel("target.com", 80);
channel.writeAndFlush(new DefaultFullHttpRequest(
HttpVersion.HTTP_1_1,
HttpMethod.GET,
longUrl
));
// 处理响应...
}
}优化效果:
- TCP连接复用率提升10倍
- 减少80%的TCP握手开销
- QPS承载能力提升3倍
5 百万QPS整体架构
百万QPS整体架构如下图所示: 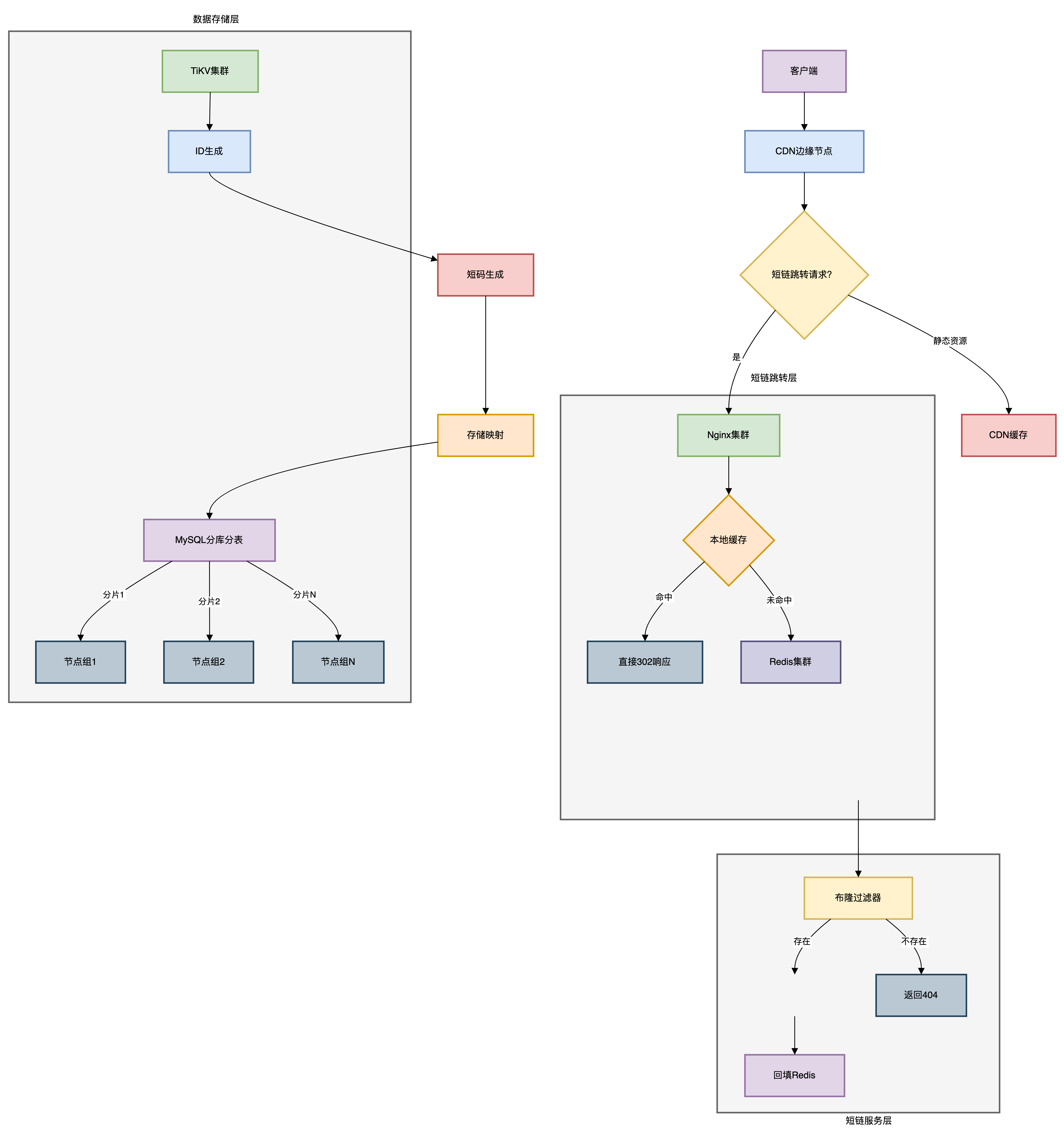
核心组件解析:
接入层
- CDN:缓存静态资源
- Nginx:处理302跳转,本地缓存热点数据
缓存层
- Redis集群:缓存短链映射
- 布隆过滤器:拦截非法请求
服务层
- 短链生成:分布式ID服务
- 映射查询:高并发查询服务
存储层
- MySQL:分库分表存储映射关系
- TiKV:分布式KV存储ID生成状态
6 容灾设计
6.1 限流熔断策略
基于Sentinel的熔断降级:
public class RedirectController {
@GetMapping("/{shortCode}")
@SentinelResource(
value = "redirectService",
fallback = "fallbackRedirect",
blockHandler = "blockRedirect"
)
public ResponseEntity redirect(@PathVariable String shortCode) {
// 跳转逻辑...
}
// 熔断降级方法
public ResponseEntity fallbackRedirect(String shortCode, Throwable ex) {
return ResponseEntity.status(503)
.body("服务暂时不可用");
}
// 限流处理方法
public ResponseEntity blockRedirect(String shortCode, BlockException ex) {
return ResponseEntity.status(429)
.body("请求过于频繁");
}
}6.2 多级降级方案
使用多级降级方案: 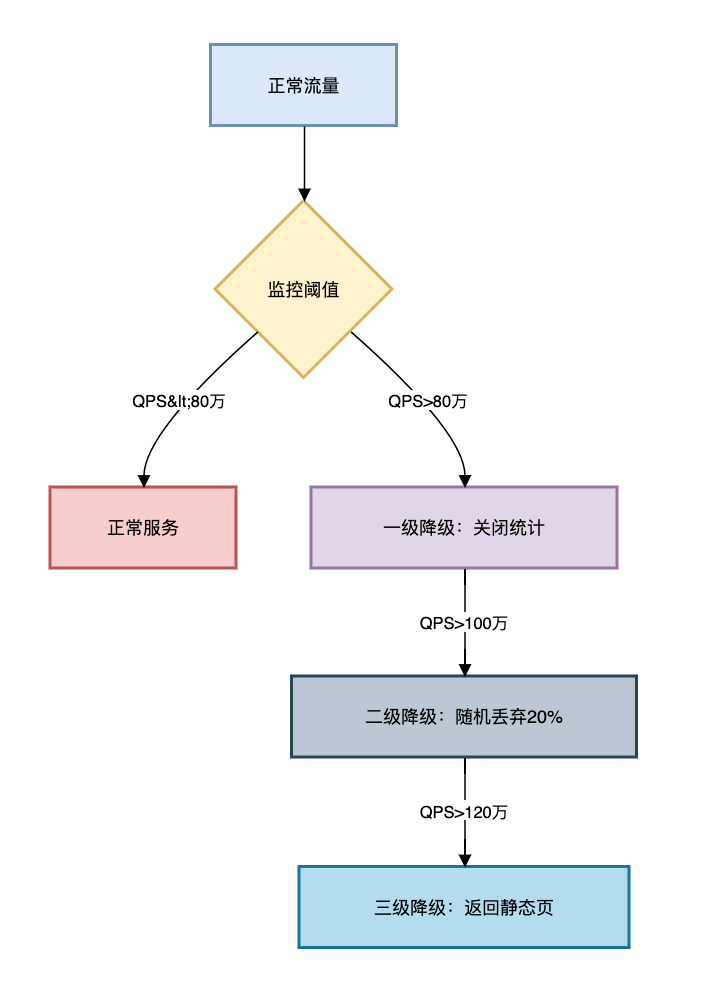 保证服务的高可用。
保证服务的高可用。
6.3 数据分片策略
基于短码分库分表:
public int determineDbShard(String shortCode) {
// 取短码首字母的ASCII值
int ascii = (int) shortCode.charAt(0);
// 分16个库
return ascii % 16;
}
public int determineTableShard(String shortCode) {
// 取短码的CRC32值
CRC32 crc32 = new CRC32();
crc32.update(shortCode.getBytes());
// 每库1024张表
return (int) (crc32.getValue() % 1024);
}这里成了16个库,每个库有1024张表。
7 性能压测数据对比
| 优化点 | 优化前QPS | 优化后QPS | 提升倍数 |
|---|---|---|---|
| 原始方案 | 12,000 | - | 1x |
| +Redis缓存 | 120,000 | 10x | |
| +Nginx直跳 | 350,000 | 2.9x | |
| +连接池优化 | 780,000 | 2.2x | |
| +布隆过滤器 | 1,200,000 | 1.5x |
压测环境:32核64G服务器 × 10台,千兆内网
总结
百万QPS短链架构核心要点如图所示: 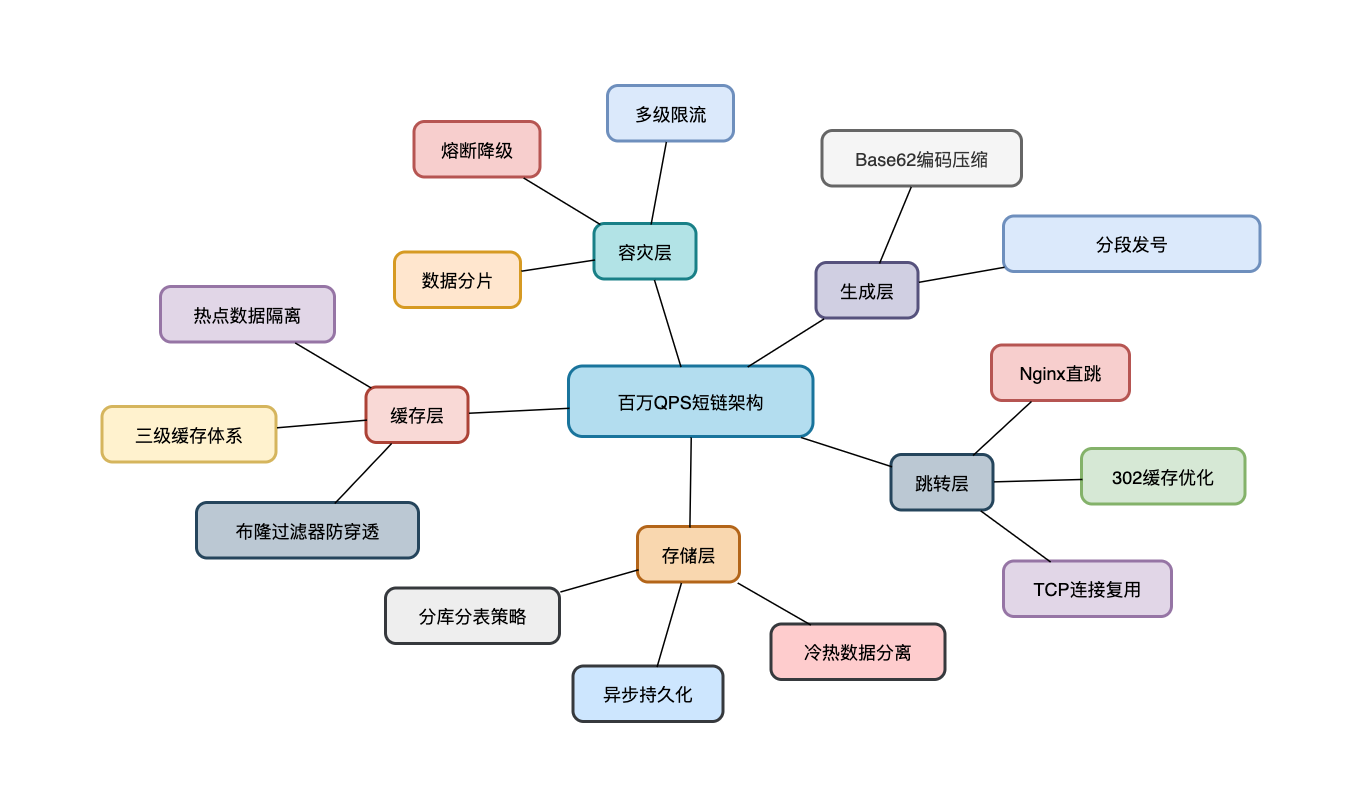
四大设计原则:
- 无状态设计:跳转服务完全无状态,支持无限扩展
- 读多写少优化:将读性能压榨到极致
- 分而治之:数据分片,流量分散
- 柔性可用:宁可部分降级,不可全线崩溃
真正的架构艺术不在于复杂,而在于在百万QPS洪流中,用最简单的路径解决问题。当你的系统能在流量风暴中优雅舞蹈,才是架构师的巅峰时刻。