01 智能代码审查系统项目介绍:规则引擎 + 大模型审查 + CI/CD 门禁,一套可落地的工程化审查平台
01 智能代码审查系统项目介绍:让“代码审查”从人工经验,变成可门禁的工程系统
很多团队都做过“代码审查”,但通常只停留在两种形态:
- 形态 A:靠资深同学的经验,但无法规模化、难持续
- 形态 B:接了几个扫描器,但难以融入研发流程、难以让业务方“愿意用”
CodeGuardian 的定位更像“审查能力的工程化封装”:它把规则审查、AI 审查、缓存复用、CI/CD 门禁、Webhook 回写、报告生成统一成一个闭环,最终落在同一种数据模型 Finding 上,形成可复用的“治理底座”。
目录
- 一图看懂:系统架构与数据闭环
- 亮点 1:审查不是一次调用,而是“任务化 + 异步编排”
- 亮点 2:规则引擎与 AI 审查同一入口,按需切换
- 亮点 3:语义指纹缓存,解决“重复审查”成本问题
- 亮点 4:CI/CD 质量门禁,从报告走向“可阻断”
- 亮点 5:Webhook 回写,把审查融入 MR 协作流
- 亮点 6:报告生成,统一输出给人看的“工程化结果”
- 亮点 7:多入口审查能力,覆盖片段/文件/目录/项目/Git
- 亮点 8:范围治理可配置:include/exclude 扫描过滤一体化
- 亮点 9:目录/项目并行审查:线程池化 + 相对路径定位
- 亮点 10:配置中心:规则标准/范围/展示上限/可视化参数可运营
- 亮点 11:前端体验与降级:未配置大模型自动切到“仅规则审查”
- 亮点 12:权限分层:REVIEW/QUERY/CONFIG 等能力边界清晰
- 亮点 13(AI):多模型提供方适配与自动降级(面试高频)
- 亮点 14(AI):提示词即协议:结构化输出 + 行号对齐 + Diff(面试高频)
- 亮点 15(AI):输出解析鲁棒性:从“模型文本”稳定落到 Finding(面试高频)
- 亮点 16(AI):Function Calling 工具链:可插拔工具 + Schema 自动生成(面试高频)
- 亮点 17(AI):RAG 工程化:混合检索 + 向量维度自愈 + 默认知识库(面试高频)
- 最适合用它做的五件事
- 加入星球
一图看懂:系统架构与数据闭环
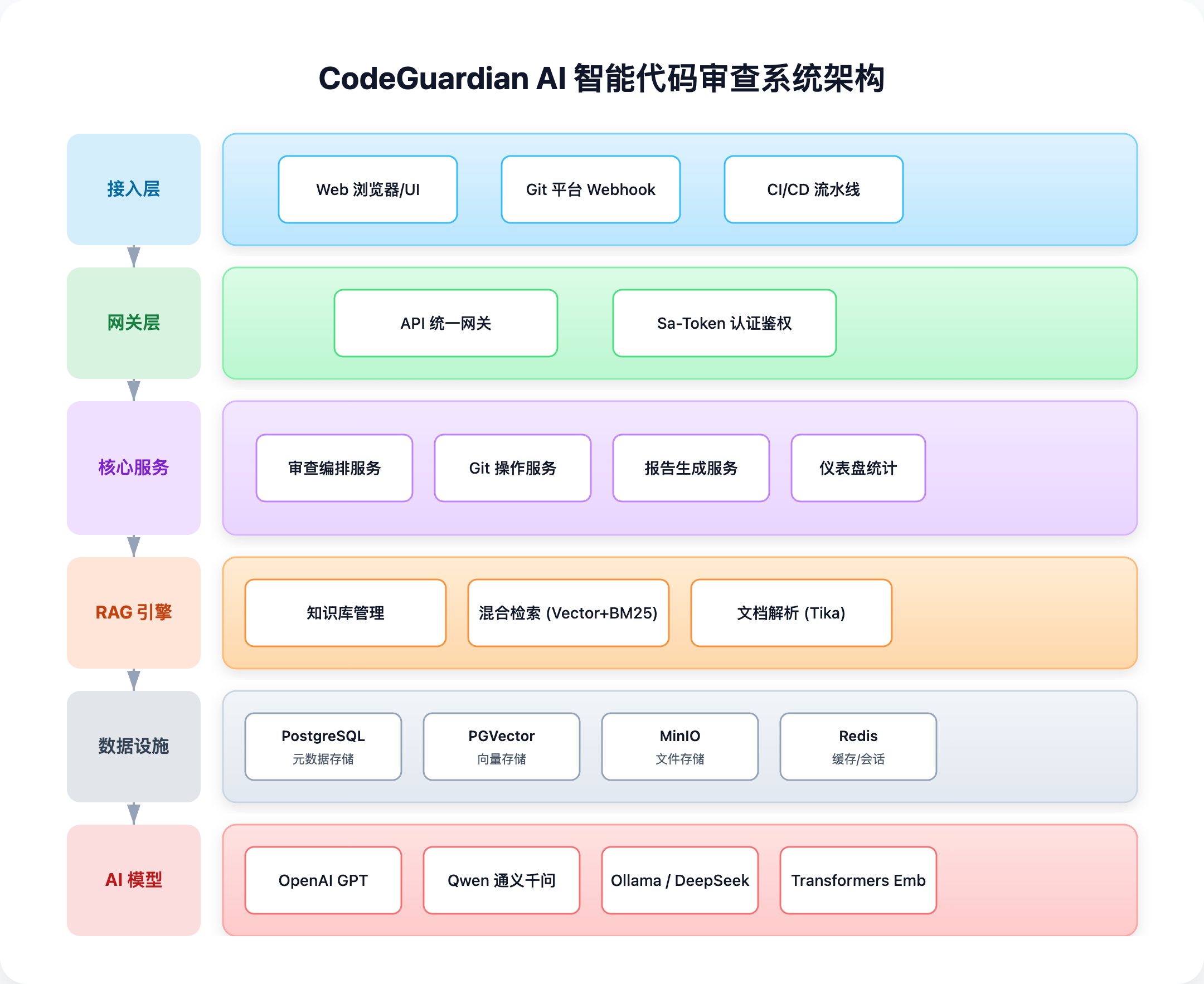
这个图强调了一个工程化原则:审查不应是“把模型跑一遍”,而应是“产出可被系统消费的结构化结果(Finding)”。 只要 Finding 模型稳定,门禁、报告、看板、统计都可以复用同一套链路。
页面效果
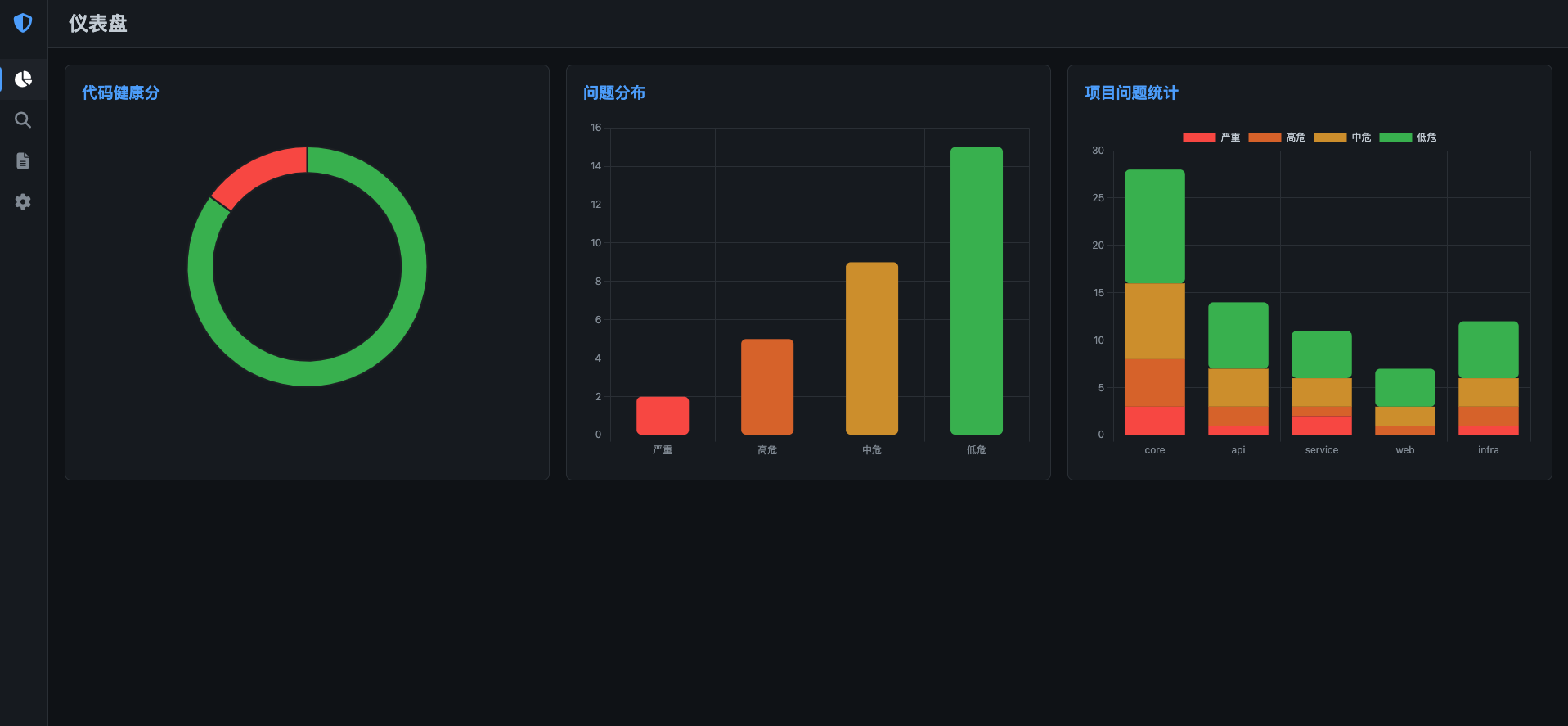
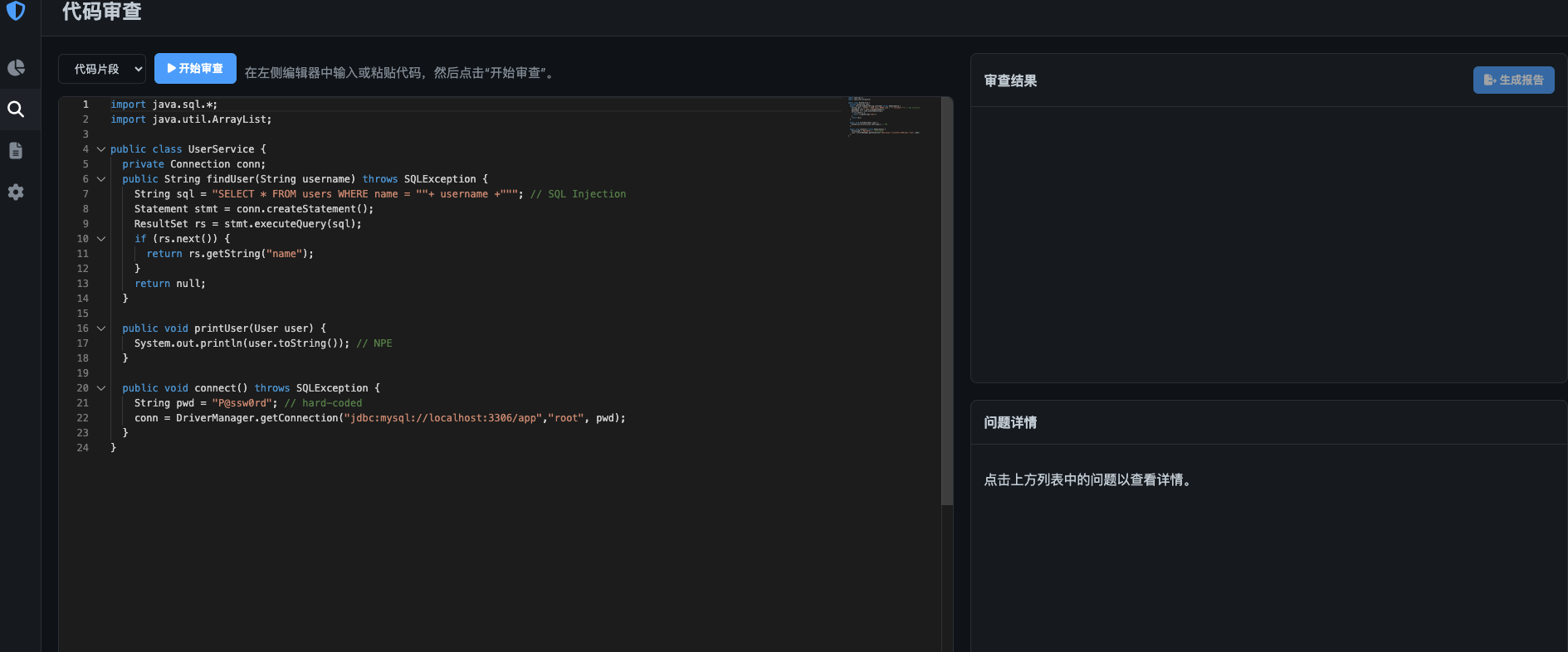
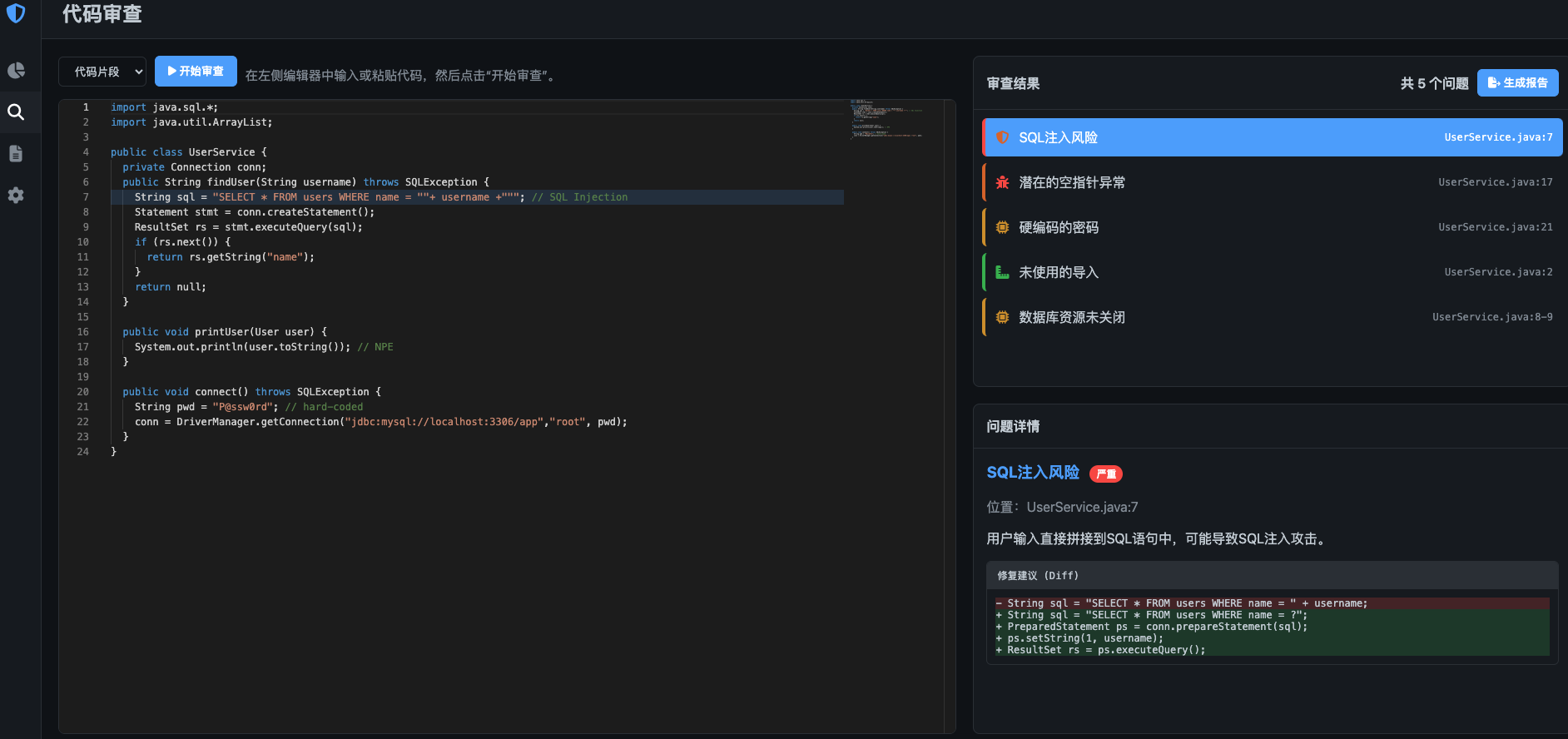
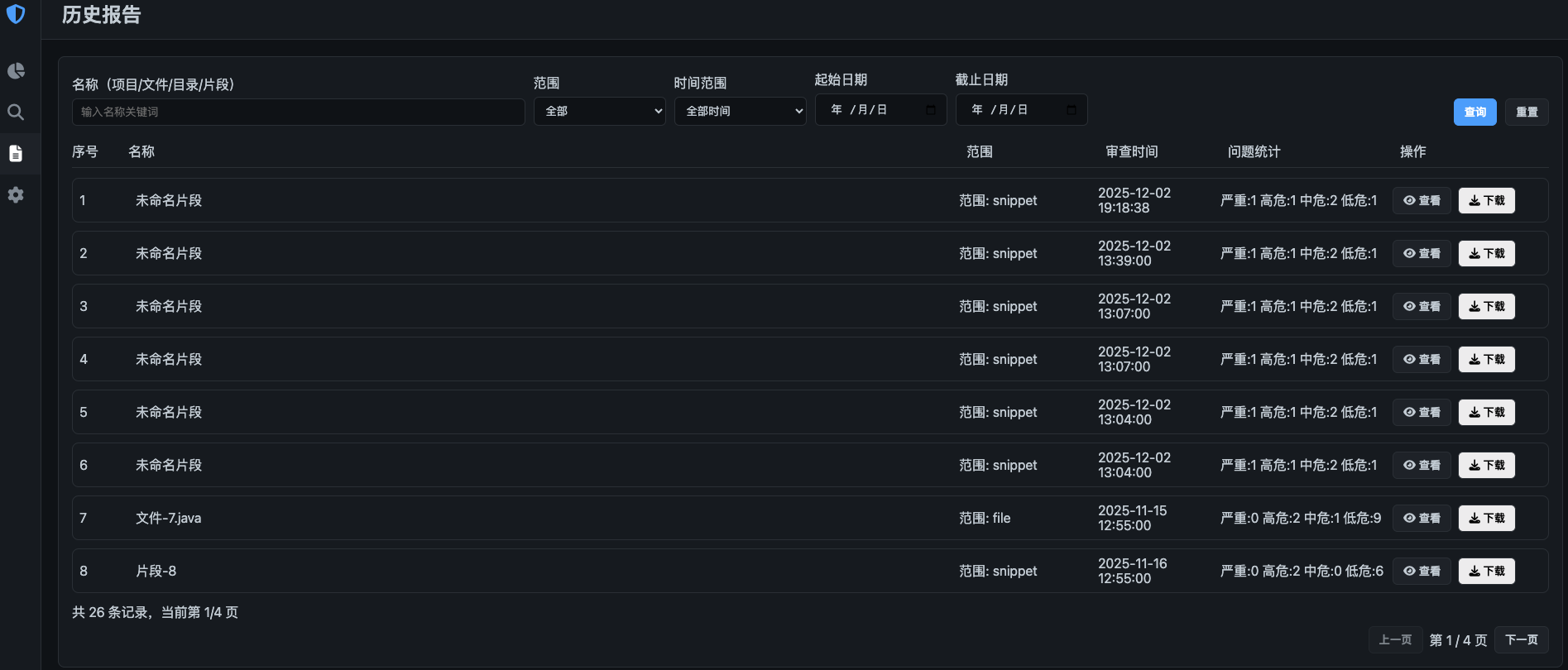
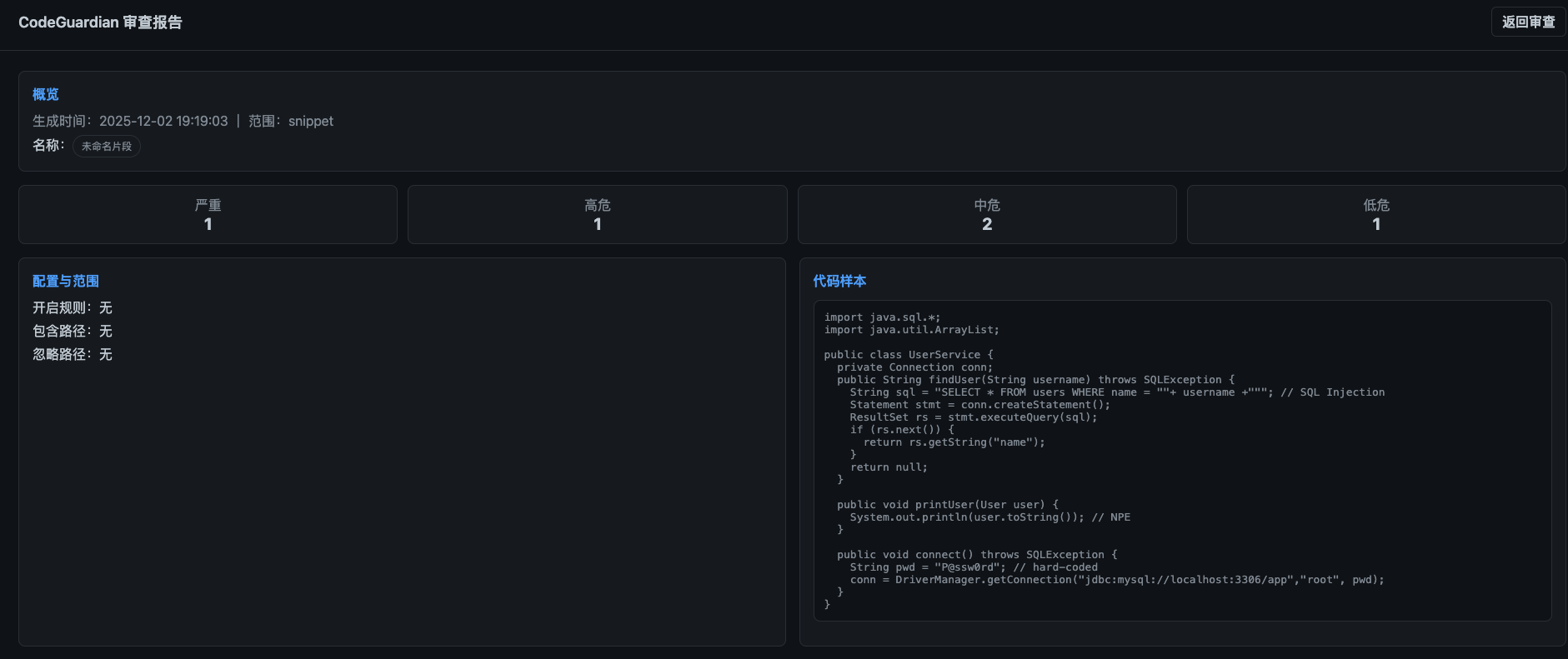
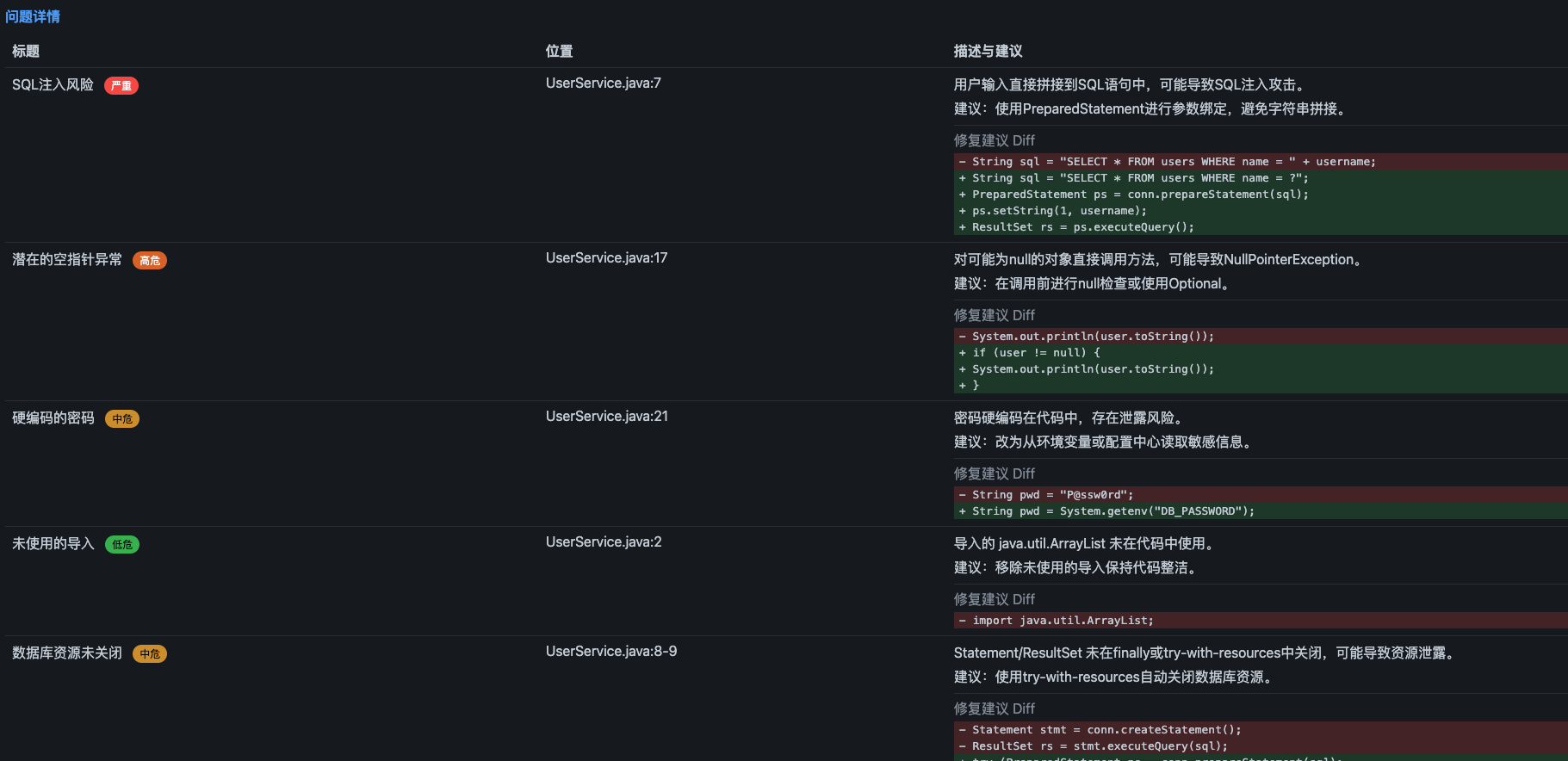
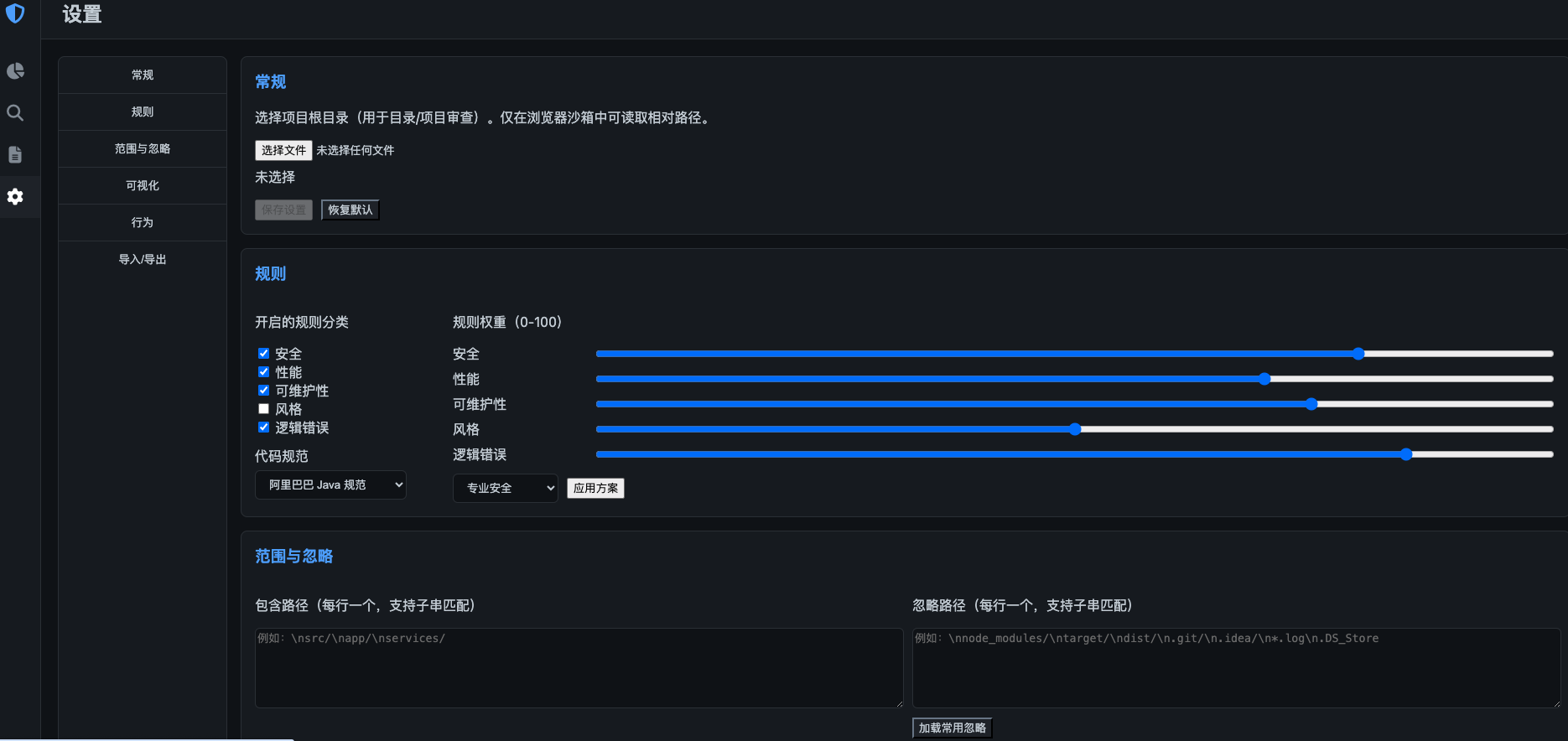
代码结构如下:
亮点 1:审查不是一次调用,而是“任务化 + 异步编排”
审查任务入口在 ReviewService.java 的 createReviewTask。它把“审查”定义成一类任务,并且把执行放到事务提交之后异步触发,避免请求线程被阻塞。
@Transactional
public ReviewResponseDTO createReviewTask(ReviewRequestDTO request) {
ReviewTask task = ReviewTask.builder()
.name(request.getTaskName() != null ? request.getTaskName() : generateTaskName(request))
.reviewType(ReviewTypeEnum.fromName(request.getReviewType()).getValue())
.scope(determineScope(request))
.status(TaskStatusEnum.RUNNING.getValue())
.createdAt(LocalDateTime.now())
.build();
task = taskRepository.save(task);
ReviewTask finalTask = task;
Long taskId = task.getId();
Runnable reviewJob = () -> runReviewAsync(taskId, finalTask, request);
if (TransactionSynchronizationManager.isActualTransactionActive()) {
TransactionSynchronizationManager.registerSynchronization(new TransactionSynchronization() {
@Override
public void afterCommit() {
orchestrationExecutor.submit(reviewJob);
}
});
} else {
orchestrationExecutor.submit(reviewJob);
}
return buildResponseDTO(finalTask);
}这里的“专业感”来自两个点:
- 事务后置:任务写入成功后再异步执行,避免出现“任务没落库但线程已经开始跑”的一致性问题
- 统一任务模型:无论来自 UI、CI/CD、Webhook,都是同一套任务体系(便于治理与统计)
亮点 2:规则引擎与 AI 审查同一入口,按需切换
真正决定“走规则还是走 AI”的地方在 ReviewService.java 的 executeReviewStrategy。rulesOnly=true 时不会调用大模型,适合离线/低成本/强确定性场景。
boolean useRulesOnly = Boolean.TRUE.equals(request.getRulesOnly());
if (useRulesOnly) {
if ("CUSTOM".equalsIgnoreCase(request.getRuleTemplate())) {
findings = ruleEngineService.reviewWithCustom(codeContent, request.getCustomRules());
} else {
findings = ruleEngineService.reviewWithTemplate(codeContent, request.getLanguage(), request.getRuleTemplate());
}
if (findings != null) {
findings.forEach(f -> f.setSource("RuleEngine"));
}
} else {
// 走 AI 审查(可叠加缓存与 RAG)
}规则引擎本身是模板化的正则规则扫描:RuleEngineService.java 的 applyRules 会把命中统一转成 Finding:
Pattern p = Pattern.compile(rule.getPattern(), Pattern.MULTILINE);
Matcher m = p.matcher(code);
while (m.find()) {
int line = computeLineNumber(code, m.start());
findings.add(Finding.builder()
.severity(SeverityEnum.fromName(rule.getSeverity()).getValue())
.title(rule.getName())
.location("Line " + line)
.startLine(line)
.endLine(line)
.description(rule.getDescription())
.suggestion(rule.getSuggestion())
.category("CODE_STYLE")
.build());
}工程边界与适用范围:
- 当前规则引擎基于 Regex,适合风格/简单禁用项/部分安全禁用项,不适合 AST 语义规则
endLine当前按单行展示,未输出多行范围与命中片段 diff
亮点 3:语义指纹缓存,解决“重复审查”成本问题
在真实落地中,一个常见疑问是:“同一段代码反复跑模型,成本和延迟怎么控?”
项目里给出的工程答案是:对代码块做归一化指纹缓存,ExactHash 负责 100% 命中,SimHash 负责“相似命中”。核心逻辑在 SemanticFingerprintCacheService.java 的 tryGetCachedFindings:
public Optional<List<Finding>> tryGetCachedFindings(String codeContent, String language, ModelProviderEnum provider, boolean enableRag, int blockStartLine) {
if (!isCacheEnabled() || isBlank(codeContent)) {
return Optional.empty();
}
FingerprintContext ctx = buildFingerprintContext(codeContent, language, provider, enableRag);
CacheEntry exactEntry = safeGetEntry(ctx.getExactKey());
if (exactEntry != null) {
return Optional.of(toFindings(exactEntry, blockStartLine));
}
CacheEntry nearest = findNearestBySimHash(ctx.getScopePrefix(), ctx.getSimHash64(), ctx.getExactHash());
if (nearest != null) {
return Optional.of(toFindings(nearest, blockStartLine));
}
return Optional.empty();
}这一实现体现三点工程价值:
- 隔离维度完整:缓存 key 会包含语言、模型、RAG 开关等维度,避免误复用
- 可降级:Redis 不可用时“视为不命中”,不会影响主审查流程(稳定性优先)
- 复用的是结构化结果:命中后直接返回
Finding,下游门禁/报告不需要感知来源
亮点 4:CI/CD 质量门禁,从报告走向“可阻断”
真正能让研发团队“愿意用”的关键,不是审查报告,而是门禁:能不能在流水线里给出可解释、可配置的 pass/fail。
项目直接提供 CI/CD 入口:CicdController.java。
触发审查(返回 taskId,供流水线轮询):
@PostMapping("/trigger")
public ResponseEntity<CicdStatusResponse> triggerReview(@RequestBody CicdTriggerRequest request) {
ReviewRequestDTO reviewRequest = ReviewRequestDTO.builder()
.reviewType("GIT")
.gitUrl(request.getGitUrl())
.taskName("CI-" + (request.getTriggerBy() != null ? request.getTriggerBy() : "AUTO") + "-" + System.currentTimeMillis())
.build();
ReviewResponseDTO taskResponse = reviewService.createReviewTask(reviewRequest);
return ResponseEntity.ok(CicdStatusResponse.builder()
.taskId(taskResponse.getTaskId())
.status(TaskStatusEnum.RUNNING.name())
.passed(true)
.message("任务已提交,请轮询状态接口")
.build());
}轮询并按严重级别阻断(blockOn 默认 CRITICAL):QualityGateService.java 的 checkQualityGate
switch (blockOn.toUpperCase()) {
case "LOW":
if (low > 0) return false;
case "MEDIUM":
if (medium > 0) return false;
case "HIGH":
if (high > 0) return false;
case "CRITICAL":
if (critical > 0) return false;
break;
default:
return true;
}
return true;门禁的工程价值在于:它不是“写死的规则”,而是把质量要求变成清晰可配置的契约 —— 可以对不同仓库/分支设置不同阻断级别,支持渐进式治理。
亮点 5:Webhook 回写,把审查融入 MR 协作流
CI 门禁解决的是“能不能合”,Webhook 回写解决的是“怎么协作”。
Webhook 入口在 WebhookController.java 的 handleGitCodeWebhook,对 MR open/update/reopen 事件异步触发审查。
更关键的是它会回写 MR 状态与评论(commit status + note):WebhookController.java 的 processGitCodeMr
if (commitSha != null) {
gitFeedbackService.updateStatus(gitUrl, commitSha, "pending", "CodeGuardian AI 审查中...");
}
ReviewResponseDTO response = reviewService.createReviewTask(request);
gitFeedbackService.postComment(gitUrl, String.valueOf(mrIid),
"🤖 **CodeGuardian AI** 已开始审查此 MR。\n\n" +
"任务 ID: `" + response.getTaskId() + "`\n" +
"请等待后续审查报告。");而回写服务本身也考虑了“可演示、可落地”的现实问题:Token 未配置时会降级为模拟发送,不阻塞主流程:GitFeedbackService.java 的 postComment
if (token == null || token.isEmpty()) {
log.warn("未配置 GitCode Token,跳过发送评论。");
log.info("模拟发送评论到 {} #{}: {}", gitUrl, prNumber, comment);
return;
}这段“降级策略”体现了工程化的可用性:即使缺少 Git 平台 Token,系统也不会阻塞主流程,而是保持行为可预期。
亮点 6:报告生成,统一输出给人看的“工程化结果”
做审查平台最终要服务两类人:
- 研发:想快速定位问题与修复建议
- 负责人/治理方:想看到汇总、趋势与门禁结果
项目把结果统一存为 Finding,报告生成从 Finding 渲染,入口在 ReportService.java 的 generateReport:
public ReviewReport generateReport(Long taskId) {
ReviewTask task = taskRepository.findById(taskId)
.orElseThrow(() -> new IllegalStateException("任务不存在: " + taskId));
if (!TaskStatusEnum.COMPLETED.getValue().equals(task.getStatus())) {
throw new IllegalStateException("任务未完成,无法生成报告: " + taskId);
}
ReviewReport existingReport = reportRepository.findByTaskId(taskId).orElse(null);
if (existingReport != null) {
return existingReport;
}
List<Finding> findings = findingRepository.findByTaskId(taskId);
int maxIssues = systemConfigService.getSettings().getMaxIssues();
String markdownContent = generateMarkdownReport(task, findings, maxIssues);
String htmlContent = generateHTMLReport(task, findings, maxIssues);
ReviewReport report = ReviewReport.builder()
.taskId(task.getId())
.markdownContent(markdownContent)
.htmlContent(htmlContent)
.build();
return reportRepository.save(report);
}这里体现的工程化点是:
- 报告幂等:同一个 taskId 只生成一次(有则复用)
- 展示上限可配置:
maxIssues来自系统设置,避免报告被“问题洪峰”撑爆
亮点 7:多入口审查能力,覆盖片段/文件/目录/项目/Git
推广一套“审查平台”,最怕的就是只能跑 Demo。真实团队的需求是多形态的:有人想粘贴代码片段,有人想审一个文件,有人要扫目录/项目,还有人要对 Git 仓库做完整审查。
项目把入口做成了统一 API 族,并在 Controller 层强制标注 reviewType:ReviewController.java
@PostMapping("/snippet")
@SaCheckPermission("REVIEW")
public ResponseEntity<ReviewResponseDTO> reviewSnippet(@Valid @RequestBody ReviewRequestDTO request) {
request.setReviewType("SNIPPET");
ReviewResponseDTO response = reviewService.createReviewTask(request);
return ResponseEntity.ok(response);
}
@PostMapping("/git")
@SaCheckPermission("REVIEW")
public ResponseEntity<ReviewResponseDTO> reviewGitProject(@Valid @RequestBody ReviewRequestDTO request) {
request.setReviewType("GIT");
ReviewResponseDTO response = reviewService.createReviewTask(request);
return ResponseEntity.ok(response);
}更关键的是:Git 审查在执行层支持“未克隆则自动克隆”,把一线使用的摩擦做到最低:ReviewService.java 的 performReview
if ("GIT".equals(type)) {
if (request.getProjectPath() == null && request.getGitUrl() != null) {
String localPath = gitService.cloneRepository(request.getGitUrl(), request.getGitUsername(), request.getGitPassword());
request.setProjectPath(localPath);
task.setScope(localPath);
taskRepository.save(task);
}
performParallelReview(task, request);
}亮点 8:范围治理可配置:include/exclude 扫描过滤一体化
真正的工程项目不可能“全仓扫描”:target、.git、测试夹、生成代码、第三方拷贝目录都应被排除,否则审查噪音会让团队快速弃用。
CodeGuardian 把范围治理做成系统设置(并给出合理默认值):SystemConfigService.java 的 getSettings
dto.setIncludePaths(configMap.getOrDefault(KEY_SCOPE_INCLUDE, "src/main/java"));
dto.setExcludePaths(configMap.getOrDefault(KEY_SCOPE_EXCLUDE, "target\n.git\ntest"));
dto.setMaxIssues(parseInt(configMap.get(KEY_BEHAVIOR_MAX_ISSUES), 100));范围过滤不是“UI 上写个配置”,而是落实到扫描链路里:目录扫描会把文件路径归一化成相对路径,并执行 include/exclude 判断:CodeParserService.java 的 scanDirectory
return paths.filter(Files::isRegularFile)
.filter(this::isCodeFile)
.filter(path -> {
String relativePath = dir.relativize(path).toString().replace(java.io.File.separator, "/");
return isPathIncluded(relativePath, includes, excludes);
})
.collect(Collectors.toList());范围治理的价值在于:不是“靠人自觉”,而是“系统默认就正确”。
亮点 9:目录/项目并行审查:线程池化 + 相对路径定位
对目录/项目/Git 仓库做审查时,吞吐量决定“可用性”:如果扫一次要 30 分钟,团队不会用;如果能并行把延迟打下来,就能纳入日常流程。
项目的并行审查逻辑在 ReviewService.java 的 performParallelReview:
List<Path> files = codeParserService.scanDirectory(path, includePaths, excludePaths);
final Path rootPath = Paths.get(path).toAbsolutePath().normalize();
futures = files.stream()
.map(filePath -> executor.submit(() -> {
String content = codeParserService.readFile(filePath.toString());
String relativePath = rootPath.relativize(filePath.toAbsolutePath().normalize()).toString();
return reviewSingleFile(relativePath, content, request);
}))
.collect(Collectors.toList());这里的“专业点”在于:
- 并行化是可控的:并行单文件审查,不改变审查策略本身(规则/AI 都复用同一个
executeReviewStrategy) - 定位信息工程化:结果的
location会带上相对路径,确保报告/门禁里能直接定位文件位置
亮点 10:配置中心:规则标准/范围/展示上限/可视化参数可运营
很多项目的“配置”停留在 application.yml,导致一旦要改策略就要发版。CodeGuardian 把核心治理参数做成可持久化的系统配置,并提供校验约束,避免“把系统配置到不可用”。
设置读取与默认策略:SystemConfigService.java 的 getSettings
dto.setRuleStandard(configMap.getOrDefault(KEY_RULE_STANDARD, "alibaba"));
dto.setRulePreset(configMap.getOrDefault(KEY_RULE_PRESET, "general"));
dto.setChartHeight(parseInt(configMap.get(KEY_VIS_CHART_HEIGHT), 300));
dto.setRingThickness(parseInt(configMap.get(KEY_VIS_RING_THICKNESS), 20));关键参数校验(保证“可运营”而不失控):SystemConfigService.java 的 validateSettings
if (dto.getMaxIssues() != null && dto.getMaxIssues() < 1) {
throw new IllegalArgumentException("最大问题数必须至少为 1");
}
if (dto.getRuleWeights() != null) {
for (Integer weight : dto.getRuleWeights().values()) {
if (weight != null && (weight < 0 || weight > 100)) {
throw new IllegalArgumentException("规则权重必须在 0 到 100 之间");
}
}
}亮点 11:前端体验与降级:未配置大模型自动切到“仅规则审查”
即使未配置大模型,系统也不会“全站不可用”。前端在启动时会检测是否存在可用模型提供方:如果没有,就自动切换到“仅规则审查”并禁用切换入口,属于典型的产品级降级策略。
逻辑在 review.js:
if (!hasAvailableModelProviders) {
rulesOnlyCheckbox.checked = true;
rulesOnlyCheckbox.disabled = true;
if (rulesOnlyLabel) {
rulesOnlyLabel.textContent = '仅规则审查(未配置大模型)';
}
}这一细节的价值在于:系统默认就能跑起来,模型能力是“增强项”,不是“单点依赖”。
亮点 12:权限分层:REVIEW/QUERY/CONFIG 等能力边界清晰
审查系统天然涉及敏感数据(仓库地址、代码片段、历史报告、治理配置),如果没有权限边界,很难进入团队正式流程。
项目在接口层做了权限隔离,例如审查需要 REVIEW 权限、查询结果需要 QUERY 权限:ReviewController.java
@PostMapping("/file")
@SaCheckPermission("REVIEW")
public ResponseEntity<ReviewResponseDTO> reviewFile(@Valid @RequestBody ReviewRequestDTO request) {
request.setReviewType("FILE");
ReviewResponseDTO response = reviewService.createReviewTask(request);
return ResponseEntity.ok(response);
}
@GetMapping("/task/{taskId}/findings")
@SaCheckPermission("QUERY")
public ResponseEntity<List<FindingDTO>> getFindings(@PathVariable("taskId") Long taskId) {
// ...
}管理后台配置则要求 CONFIG 权限:SettingsController.java 的 settingsPage
@GetMapping
@SaCheckPermission("CONFIG")
public String settingsPage(Model model, HttpSession session) {
model.addAttribute("settings", configService.getSettings());
return "admin/settings";
}这种“能力边界”让系统可以直接纳入团队权限体系:谁能发起审查、谁能查询结果、谁能改治理配置,责任边界清晰。
亮点 13(AI):多模型提供方适配与自动降级(面试高频)
面试官最爱问的一个问题是:你怎么做多模型接入,怎么做 provider 选择与 fallback? 因为这直接决定了系统能否在不同环境“跑得起来”。
项目把模型接入封装在 ChatClientFactory.java:
- 通过
Map<String, ChatModel>注入不同 Provider 的实现 - 有明确的优先级顺序(QWEN/DEEPSEEK/OPENAI)
- 传入的 provider 不可用时,会自动选择其他可用模型
private static final List<ModelProviderEnum> PROVIDER_ORDER = List.of(
ModelProviderEnum.QWEN,
ModelProviderEnum.DEEPSEEK,
ModelProviderEnum.OPENAI
);
private Optional<ModelProviderEnum> resolveProvider(ModelProviderEnum provider) {
if (provider != null) {
if (chatModelMap.containsKey(provider.getCode())) {
return Optional.of(provider);
}
log.warn("未找到提供商 {} 的ChatModel,尝试使用其他可用模型", provider.getCode());
}
return getAvailableProviders().stream().findFirst();
}而在调用侧 AIModelService.java 的 reviewCode 还有“两道保险”:
if (Boolean.FALSE.equals(aiConfigProperties.getEnabled())) {
return new ArrayList<>();
}
if (!chatClientFactory.hasAvailableProviders()) {
return new ArrayList<>();
}面试官常追问:
- provider fallback 为什么要“有序”而不是随机
- 未配置模型时如何降级(空结果 vs 走规则引擎 vs 直接报错)
- 如何避免“某个模型挂了导致全站不可用”
亮点 14(AI):提示词即协议:结构化输出 + 行号对齐 + Diff(面试高频)
大多数“AI 审查 Demo”最大的问题是:输出不可控、不可解析、无法落地到工程链路。CodeGuardian 的做法是把提示词当作一份强约束协议,要求模型必须输出可解析的 JSON,并且强制行号对齐与 diff 格式。
提示词模板在 PromptService.java:
private static final String CODE_REVIEW_PROMPT_TEMPLATE = """
你是一个资深的代码审查专家。请审查以下{language}代码,识别出潜在的bug、安全漏洞、性能问题和代码风格问题。
**重要要求:**
2. 代码已经包含行号(每行前面有行号,格式为"行号: 代码内容"),请严格按照代码中显示的行号来填写startLine和endLine字段。
3. location字段必须使用"文件名:行号"格式,例如"UserService.java:7"。
6. diff字段必须使用标准的diff格式,每行以"- "(删除)或"+ "(添加)开头
请以JSON数组格式返回结果,每个问题包含以下字段:
- severity: 严重程度(CRITICAL, HIGH, MEDIUM, LOW)
- title/location/startLine/endLine/description/suggestion/diff/category
请直接返回JSON数组,不要包含其他文字说明。
""";另外它还会在构建 Prompt 前给代码加行号:PromptService.java 的 addLineNumbers
for (int i = 0; i < lines.length; i++) {
sb.append(i + 1).append(": ").append(lines[i]).append("\n");
}面试官常追问:
- 为什么“提示词协议化”是生产级 AI 应用的核心
- 为什么要强制 diff(直接把“建议”变成可执行变更)
- 行号对齐如何解决“模型胡编行号”的问题
亮点 15(AI):输出解析鲁棒性:从“模型文本”稳定落到 Finding(面试高频)
即使提示词约束很强,模型仍可能返回 Markdown code fence、夹杂解释文本、甚至返回 HTML 错误页。生产系统要做的是:尽最大可能把响应“清洗成 JSON”,否则安全失败(返回空结果)。
解析器在 CodeReviewOutputParser.java 的 parse:
String jsonStr = cleanJsonResponse(response);
if (!isValidJson(jsonStr)) {
log.error("AI响应不是有效的JSON格式");
return new ArrayList<>();
}
List<FindingDTO> findingDTOs = objectMapper.readValue(
jsonStr, new TypeReference<List<FindingDTO>>() {}
);其中清洗逻辑会去掉 ```json 代码块,并尝试截取第一个 [ 到最后一个 ] 的 JSON 数组:CodeReviewOutputParser.java 的 cleanJsonResponse
if (jsonStr.startsWith("```json")) {
jsonStr = jsonStr.substring(7).trim();
}
int firstBracket = jsonStr.indexOf('[');
int lastBracket = jsonStr.lastIndexOf(']');
if (firstBracket >= 0 && lastBracket > firstBracket) {
jsonStr = jsonStr.substring(firstBracket, lastBracket + 1);
}面试官常追问:
- 为什么“解析鲁棒性”比“模型效果”更决定落地成败
- 什么情况下选择安全失败(空列表)而不是抛异常
- 如何避免把非 JSON 响应写入报告/门禁造成误阻断
亮点 16(AI):Function Calling 工具链:可插拔工具 + Schema 自动生成(面试高频)
面试官很爱追问:你怎么让模型“会用工具”,并且把工具输出纳入最终结论?
CodeGuardian 的工具链由 ToolRegistry.java 负责注册:
- 扫描 Spring 容器内所有
Function类型 Bean - 只有带
@Description的 Function 才会被注册为“可被模型调用的工具” - 通过反射为工具输入类型生成 JSON Schema,作为 Function Calling 的入参约束
String[] beanNames = applicationContext.getBeanNamesForType(Function.class);
for (String beanName : beanNames) {
Object bean = applicationContext.getBean(beanName);
Description description = applicationContext.findAnnotationOnBean(beanName, Description.class);
if (description != null) {
registerFunctionBean(beanName, (Function<?, ?>) bean, description.value());
}
}工具调用发生时会记录调用入参,并执行 Function:ToolRegistry.java 的 getFunctionCallbacks
public String call(String functionInput) {
log.info("[Function Calling] 收到模型调用请求: 工具={}, 参数={}", getName(), functionInput);
Object result = execute(getName(), functionInput);
return objectMapper.writeValueAsString(result);
}项目内置了两个代表性工具(面试官会很喜欢这种“可演示、可解释”的工具化能力):
- Java 语法分析(JavaParser):JavaSyntaxAnalyzerTool.java
- Semgrep 安全扫描(本地 CLI):SemgrepAnalyzerTool.java
Semgrep 工具会把发现写入线程上下文,避免“模型忽略工具输出”:
SemgrepAnalyzerTool.java 的 apply
if (response.findings != null && !response.findings.isEmpty()) {
ReviewContextHolder.addFindings(response.findings);
}AI 服务会把工具发现合并回最终 findings:AIModelService.java 的 reviewCode
List<Finding> toolFindings = ReviewContextHolder.getFindings();
if (!toolFindings.isEmpty()) {
for (Finding tf : toolFindings) {
boolean exists = findings.stream().anyMatch(f ->
(f.getStartLine() != null && f.getStartLine().equals(tf.getStartLine())) &&
(f.getTitle() != null && f.getTitle().contains(tf.getTitle()))
);
if (!exists) {
findings.add(tf);
}
}
}面试官常追问:
- 为什么要有 Schema(否则工具输入不可控)
- 工具输出如何与模型结论融合(上下文注入 + 最终合并)
- 如何做去重(当前用位置+标题的简化策略,适合聊演进方向)
亮点 17(AI):RAG 工程化:混合检索 + 向量维度自愈 + 默认知识库(面试高频)
RAG 能不能落地,核心不在“能搜到”,而在“能长期稳定维护”。项目的知识库实现是典型的工程化做法:PGVector 作为向量检索底座 + 内存 BM25 支持混合检索,并且在启动时做 schema 自愈,降低运维心智负担。
知识库服务在 KnowledgeBaseService.java 的类注释里明确写了策略:
- Hybrid Retrieval(混合检索)
- PGVector(VectorStore)
- 内存 BM25(倒排索引)
它还包含一个面试官非常喜欢的“自愈”细节:向量维度不匹配时自动修复(清空并把列改成 vector(384)):KnowledgeBaseService.java 的 checkAndFixVectorSchema
if (type != null && !type.contains("(384)")) {
jdbcTemplate.execute("TRUNCATE TABLE vector_store");
jdbcTemplate.execute("ALTER TABLE vector_store ALTER COLUMN embedding TYPE vector(384)");
}当数据库为空时会自动加载默认知识库(避免“冷启动啥也搜不到”):KnowledgeBaseService.java 的 init/loadDefaultKnowledgeBase
if (dbDocs.isEmpty()) {
loadDefaultKnowledgeBase();
dbDocs = repository.findAll();
} else {
loadDefaultKnowledgeBase();
dbDocs = repository.findAll();
}而 AI 侧在启用 RAG 时会检索上下文并塞进 Prompt:AIModelService.java 的 retrieveContext
String query = "Language: " + language + "\nCode Snippet: " +
code.substring(0, Math.min(code.length(), 500));
List<String> snippets = knowledgeBaseService.searchSnippets(query, 3);面试官常追问:
- 为什么要混合检索(向量召回 + 关键词召回互补)
- 为什么要做 schema 自愈(embedding 维度变更是常见线上事故源)
- 冷启动怎么解决(默认知识库 + 可选后台向量化)
用户的反馈
有球友在简历中昨天才增加智能代码审查系统,今天就有京东的面试邀约,效果很明显:

结语:为什么这套系统容易被面试官认可?
真正容易获得点赞与转发的技术内容,往往不是“概念很大”,而是“AI 能力被工程化到可控、可复用、可门禁”:
- 它把大模型接入做成“多 Provider 适配 + 自动降级”,不是绑死某一家模型:模型不可用时系统仍能稳定运行(或切规则引擎)
- 它把提示词当作“输出协议”:强约束结构化 JSON、行号对齐、diff 变更,让 AI 输出可以被解析、被门禁、被回写
- 它把 Function Calling 工具链做成可插拔体系:工具自动注册、Schema 约束输入、工具结果回灌到最终 Findings,做到“可验证的 AI”
- 它把 RAG 做成长期可运维的知识工程:混合检索(向量 + BM25)与向量维度自愈,解决冷启动与演进期的稳定性问题
- 它把“智能”落到统一的
Finding数据模型:缓存复用、报告生成、CI/CD 门禁、Webhook 回写都围绕同一结果结构闭环运转
这套系统可以用三条主线概括:协议化(让输出可落地)、工具化(让结论可验证)、闭环化(让结果可门禁)。它把 AI 从“会说”变成“可控可用”,把审查从“建议”变成“可执行的工程治理”。
最适合用它做的五件事
- 写简历里的 AI 项目亮点:Function Calling、RAG、规则引擎、CI/CD 门禁、Webhook 回写、多模型降级,这些点非常适合写进高质量项目经历。
- 准备 AI + 工程化面试:不只是讲“大模型接入”,还能讲清楚提示词协议、结构化输出、工具链、质量门禁和审查闭环。
- 补齐可落地的 AI Agent 项目经验:很多 AI Demo 只停留在聊天,这个项目能体现真正的工程落地能力,更适合校招、社招和晋升场景。
- 做团队代码治理样板:把规则审查、AI 审查、报告生成和流水线阻断串起来,很适合拿来做团队内部 code review 规范示例。
- 学习 AI 系统设计思路:从任务编排、缓存复用、权限控制、混合检索到降级策略,这个项目能系统补齐 AI 应用的工程化视角。
加入星球
如果你想要的不只是“看懂这篇文章的亮点”,而是直接拿到完整源码、配套教程、答疑支持和项目包装思路,那么加入 Java突击队 星球会更直接。
智能代码审查系统只是其中一个代表性项目,真正的价值是把多个实战项目、AI 专题和求职提升支持,打包成一个可以持续学习和反复使用的闭环。