01 企业智能知识库系统介绍:RAG + KAG + 知识图谱 + Spring Cloud 微服务实战项目
企业智能知识库系统介绍:适合写进简历的 AI 知识库实战项目
企业智能知识库系统是一套面向企业内部知识管理、AI 智能问答、RAG 检索增强、KAG 知识增强、知识图谱分析和文档协作场景的企业级项目。
如果你正在搜索 企业智能知识库系统、企业知识库系统、AI 知识库项目、RAG 知识库实战、知识图谱项目、Spring Cloud 微服务项目 这类内容,这篇文章会系统介绍它的架构设计、技术栈、核心功能、项目亮点和适用人群。
这套系统的目标不是只做一个“能上传文档的后台”,而是把企业知识沉淀、权限治理、智能搜索、AI 问答、知识图谱和工程化架构真正串成一条完整链路。
目录
前言
最近我又肝了一个新项目:企业智能知识库系统。
这个项目非常实用,可以直接写到简历中,很加分。
一、企业智能知识库系统项目介绍
这个项目是干什么的?
简单说:让企业里的知识真正流动起来。
你在公司里是不是经常遇到这些情况:
- 找一个接口文档,要翻 Confluence、语雀、飞书、本地 Markdown,最后还是问同事才找到。
- 新同事入职,面对一片信息孤岛,没人告诉他该看什么、从哪看起。
- 核心员工离职,人走了知识也走了,留下的文档三年没更新过。
- 想用 AI 赋能知识管理,但市面上的 SaaS 方案要么太贵,要么数据安全过不了关。
企业智能知识库系统就是为解决这些问题而生的。
它覆盖了从文档创建、分类存储、混合智能检索、权限审批、版本管理,到 AI 智能问答、AI写作、知识图谱分析的全链路。
项目规模有多大?
| 维度 | 数据 |
|---|---|
| 后端微服务模块 | 10个 |
| Java 源文件 | 192个 |
| REST API 端点 | 近200个 |
| 前端功能页面 | 34个 |
| 数据库(MySQL) | 9个,共 29 张业务表 |
| 中间件集成 | 7种(Redis、ES、MongoDB、Neo4j、RabbitMQ、Nacos、RustFS) |
| 后端代码量 | 20,000+ 行 Java |
| 前端代码量 | 16,000+ 行 TypeScript/TSX |
| 总代码量 | 36,000+ 行 |
它是按照阿里巴巴 Java 开发规范、遵循企业级架构标准的生产级系统。
系统架构一览
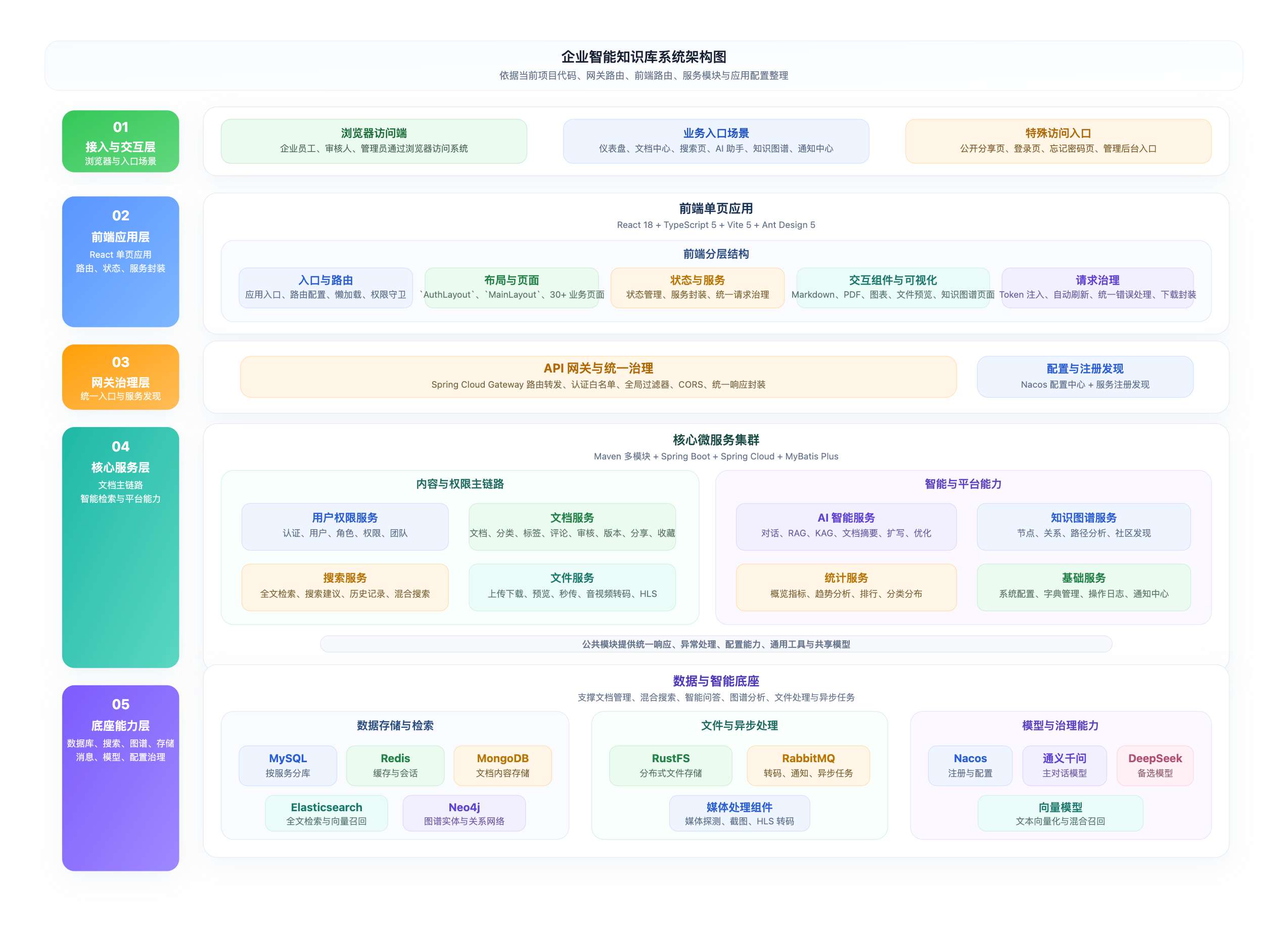
二、企业智能知识库系统使用技术
后端技术栈
| 技术 | 版本 | 在项目里的实际用途 |
|---|---|---|
| Java | 21 LTS | 虚拟线程、Record类、模式匹配 |
| Spring Boot | 3.2.0 | 所有微服务的基础框架 |
| Spring Cloud | 2023.0.0 | 微服务治理、服务间调用 |
| Spring Cloud Alibaba | 2023.0.1.0 | Nacos 注册中心 & 配置中心集成 |
| Spring Cloud Gateway | - | 统一 API 网关、路由转发、CORS |
| MyBatis Plus | 3.5.8 | 所有数据库的 ORM 操作 |
| Druid | 1.2.20 | 数据库连接池 + SQL 监控 |
| MySQL | 8.0 | 9 个业务数据库,22+ 张表 |
| Redis | 7.x | 缓存、Session、实时排行榜 |
| Elasticsearch | 7.x | 全文检索 + 向量存储 |
| MongoDB | 6.x | 文档正文内容存储 |
| Neo4j | 5.x | 知识图谱节点和关系存储 |
| RabbitMQ | 3.x | 异步消息(转码、索引同步、通知) |
| LangChain4j | 0.29.1 | LLM 集成框架,统一模型调用 |
| Knife4j | 4.3.0 | 自动生成 Swagger API 文档 |
| JWT (JJWT) | 0.12.3 | 无状态身份认证 |
| Hutool | 5.8.24 | 通用工具库 |
前端技术栈
| 技术 | 版本 | 在项目里的实际用途 |
|---|---|---|
| React | 18.3.1 | 核心 UI 框架 |
| TypeScript | 5.3.3 | 严格模式,零类型错误 |
| Vite | 5.1.0 | 构建工具,SWC 编译,秒级热更新 |
| Ant Design | 5.14.0 | 企业级 UI 组件库,中文 locale |
| React Router | 6.22.0 | 客户端路由 + 懒加载 + 权限守卫 |
| Zustand | 4.5.0 | 轻量级状态管理 + persist 持久化 |
| Axios | 1.6.7 | HTTP 请求 + token 自动刷新 + 重试队列 |
| ECharts | 5.6.0 | 数据可视化图表 |
| react-markdown | 9.0.1 | Markdown 渲染 + GFM 支持 |
| react-syntax-highlighter | 16.1.1 | 代码块语法高亮 |
| react-pdf | 10.4.1 | PDF 在线预览 |
| mammoth | 1.8.0 | DOCX 转 HTML 预览 |
| xlsx | 0.18.5 | Excel 表格解析和预览 |
中间件 & 基础设施
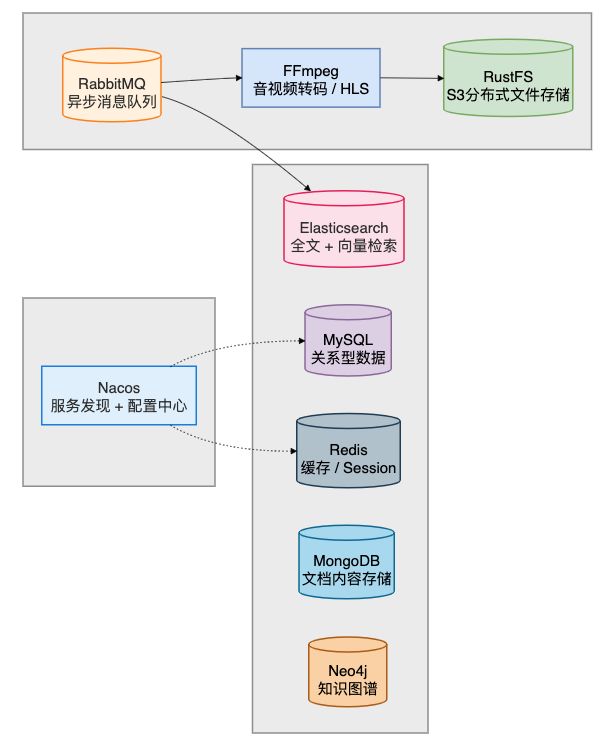
三、企业智能知识库系统功能介绍
这系统不是一个 CRUD 壳子。
我把最核心的功能一个一个拆开来说。
3.1 文档全生命周期管理
从一篇文档的诞生到归档,每个环节都管到了:
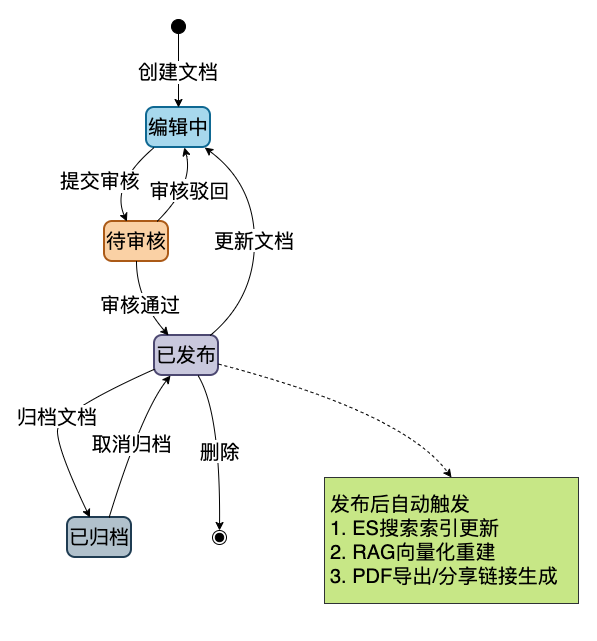
详细功能清单:
- Markdown 编辑器:实时预览、代码块语法高亮、表格、数学公式、GFM 支持
- 版本管理:每次修改自动存一版,支持版本对比和任意版本回滚
- 审批流程:文档发布需审核,审核人可以批通过也可以驳回并给出修改意见
- 分类体系:无限级联分类树,支持拖拽移动
- 标签系统:灵活打标签,热门标签自动排序
- 评论互动:可对文档评论、回复、点赞
- 收藏 & 点赞:社区化的知识互动机制
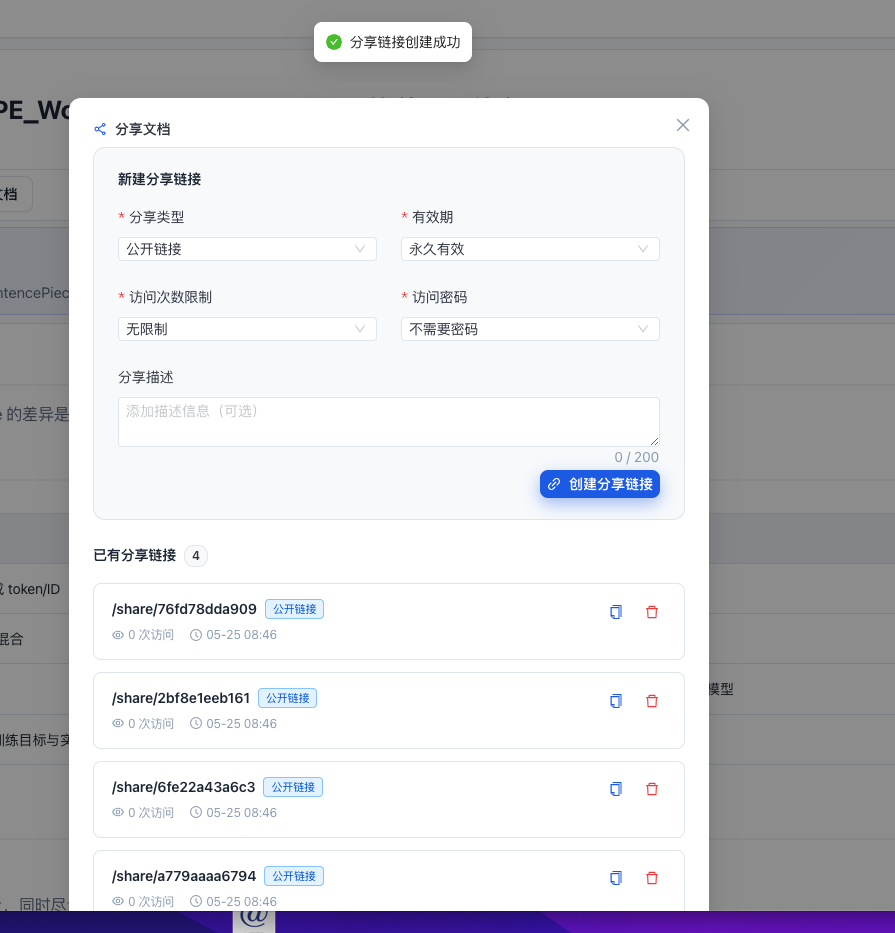
- 文档分享:生成带密码保护的分享链接,可设置有效期
- PDF 导出:一键导出 Markdown → PDF
- 文档导入:支持 Word (.docx) / Markdown (.md) / 纯文本批量导入
- 最近访问:自动记录浏览历史,方便快速回溯
- 草稿箱:未完成的文档自动保存为草稿
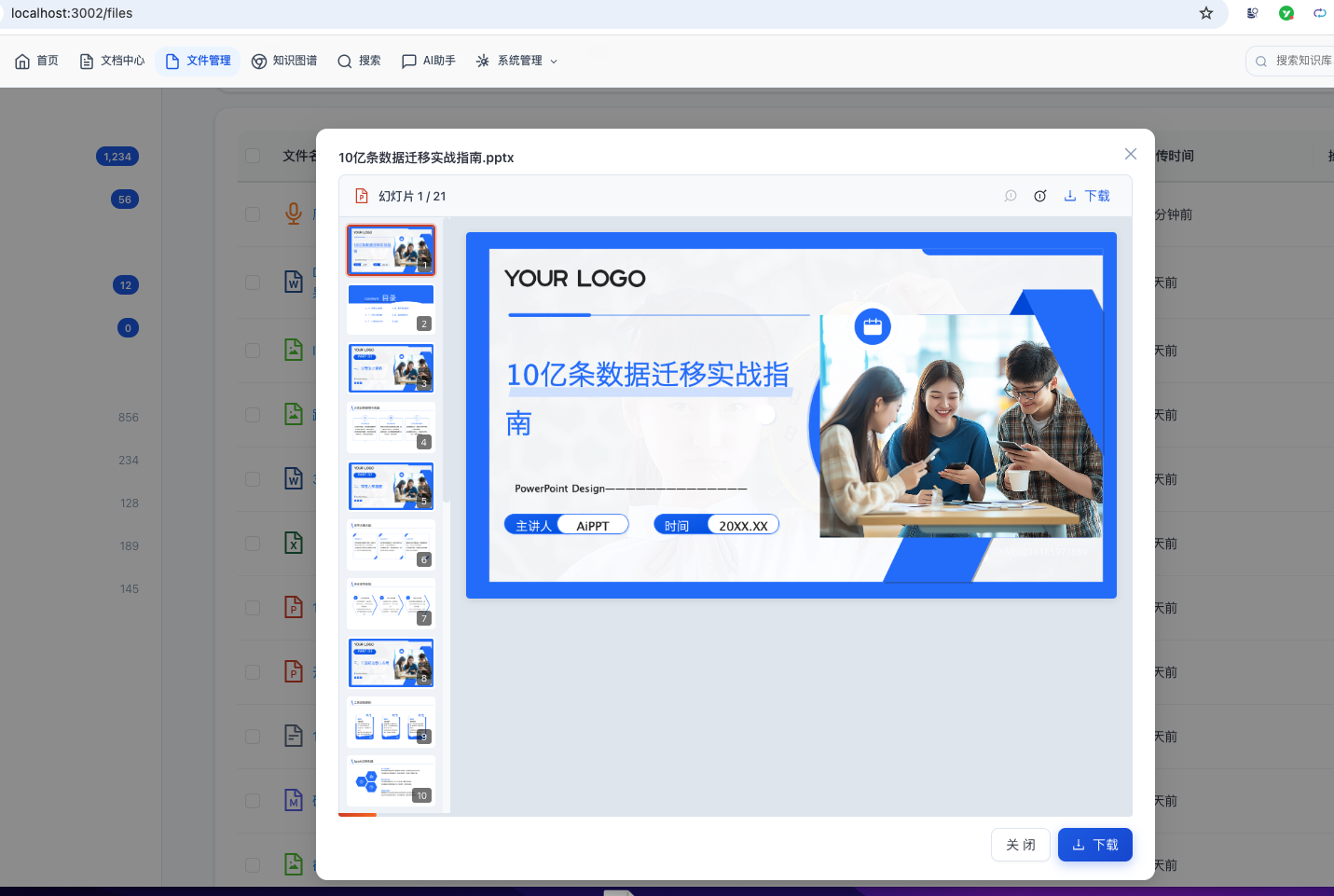
3.2 文件管理中心
统一的文件管理平台,不只是存文件,而是全格式在线预览:
| 类别 | 支持格式 | 预览方式 |
|---|---|---|
| react-pdf 渲染,支持缩放、翻页 | ||
| Word | .doc / .docx | mammoth 转 HTML 渲染 |
| Excel | .xls / .xlsx | SheetJS 解析为交互式表格 |
| PPT | .ppt / .pptx | 后端提取幻灯片为图片预览 |
| Markdown | .md | react-markdown + 代码高亮 |
| 纯文本 | .txt | 等宽字体渲染 |
| 图片 | .png / .jpg / .gif / .bmp / .svg | 原生预览 + 缩略图 |
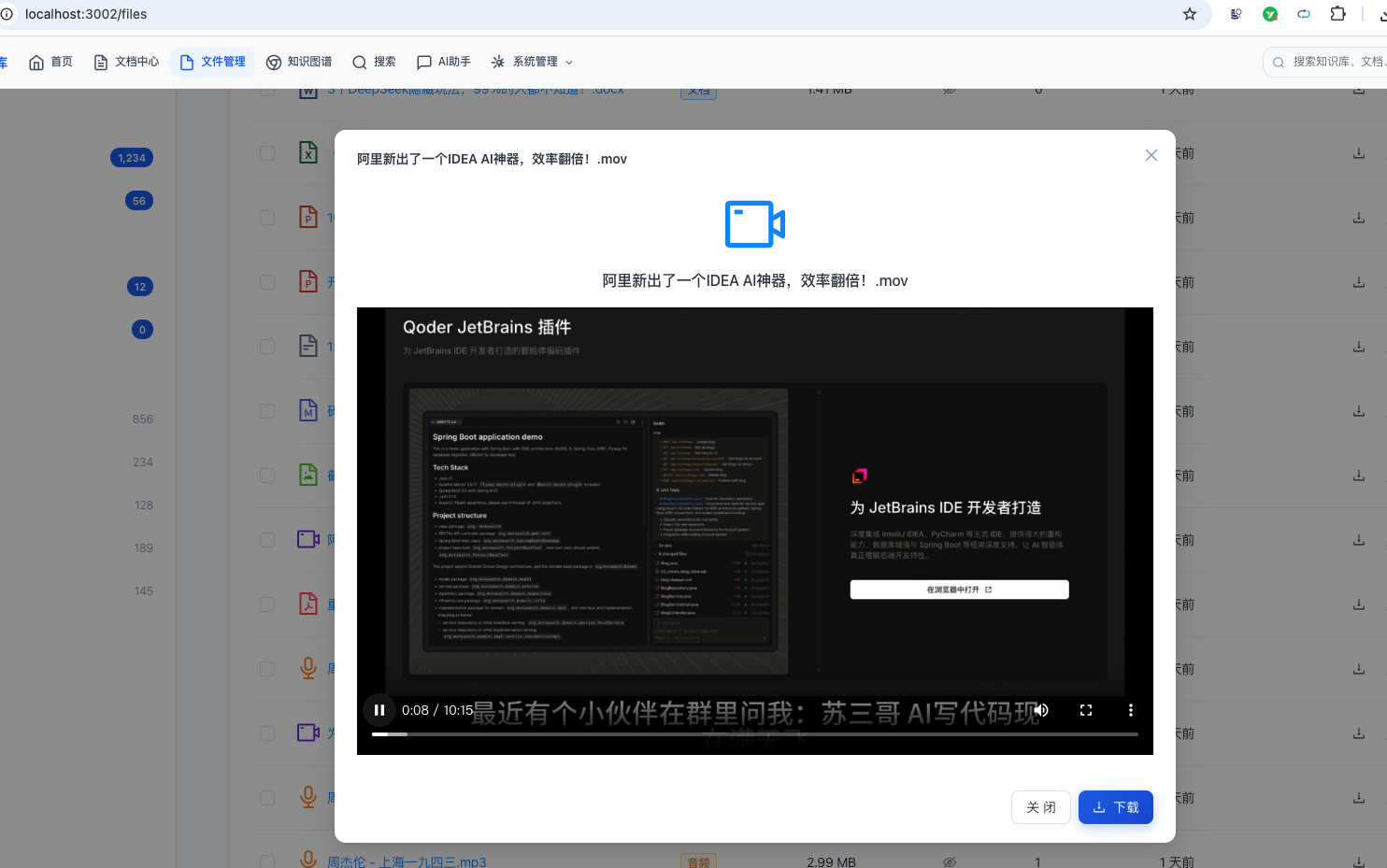
| 视频 | .mp4 / .avi / .mov / .mkv / .webm | HTML5 Video + HLS 自适应码率 |
| 音频 | .mp3 / .wav / .flac / .aac / .ogg | HTML5 Audio 播放 |
| 压缩包 | .zip / .rar / .7z | 文件列表展示 |
视频文件还支持:
- 大文件上传:最大 2GB
- 自动 HLS 转码:FFmpeg 异步转码,生成 360p + 720p 多码率
- 自适应码率播放:根据网络自动切换清晰度
- SHA-256 秒传:相同文件不重复上传
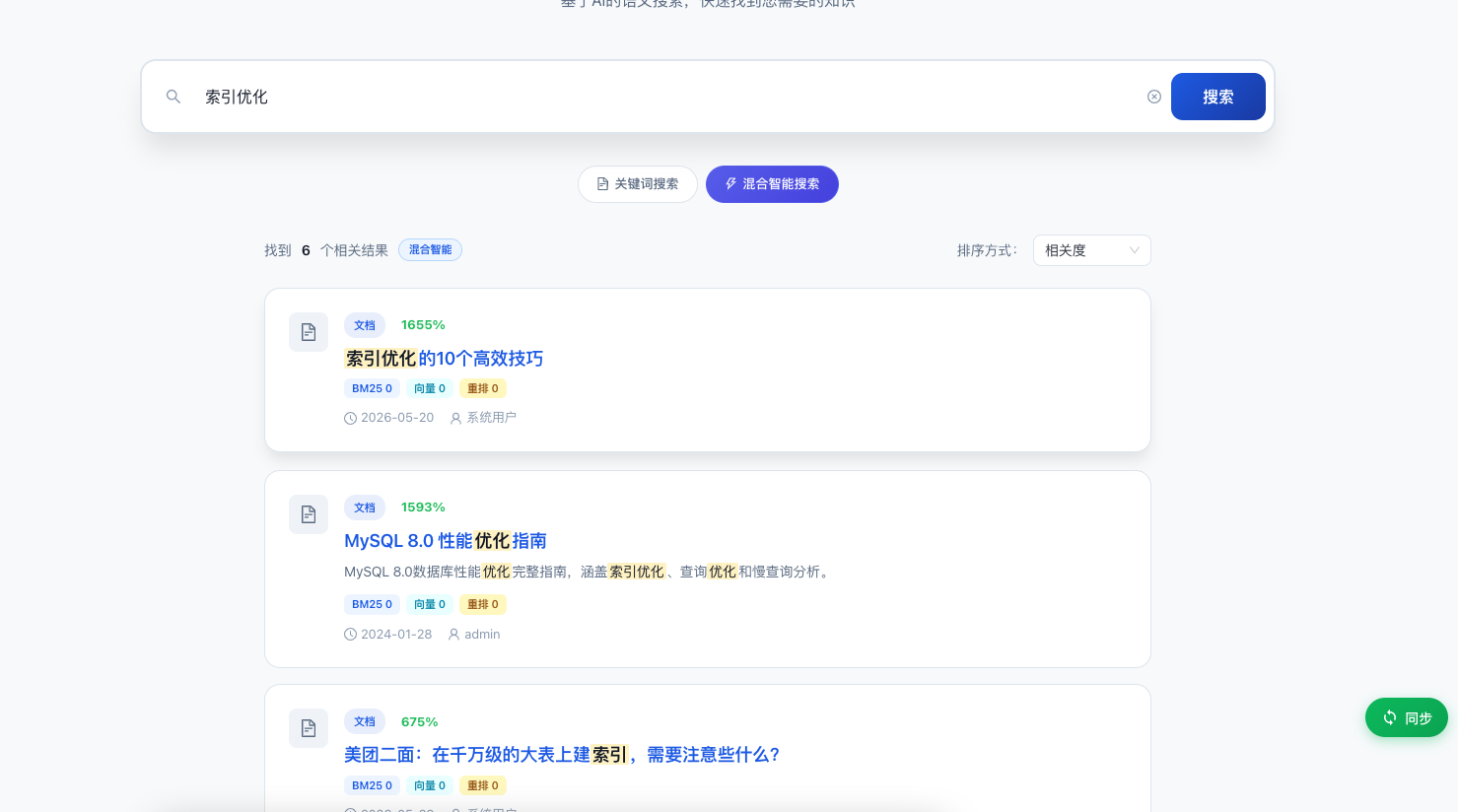
3.3 智能搜索
这不是简单的数据库 LIKE 模糊查询,而是基于 Elasticsearch 的企业级搜索引擎:
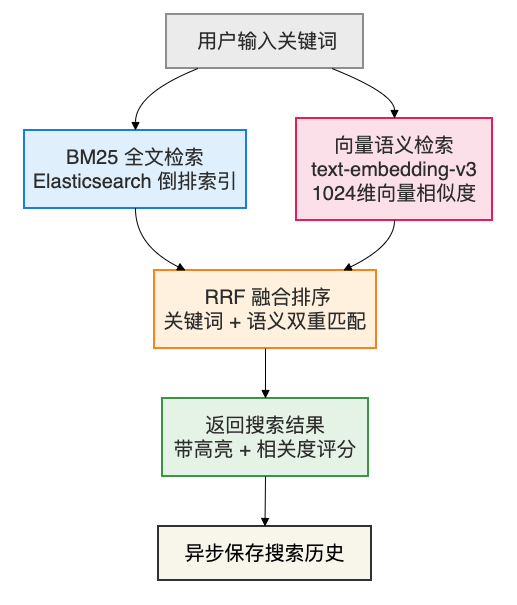
搜索能力:
- 全文搜索:输入任何关键词,秒级返回匹配文档
- 高级搜索:按分类、标签、作者、时间范围多维筛选
- 搜索建议:输入时实时联想补全
- 语义搜索:搜"怎么提高系统性能",能匹配到"性能优化"相关文档
- 热词排行:展示全系统搜索最多的关键词
- 搜索历史:自动保存,随时回顾
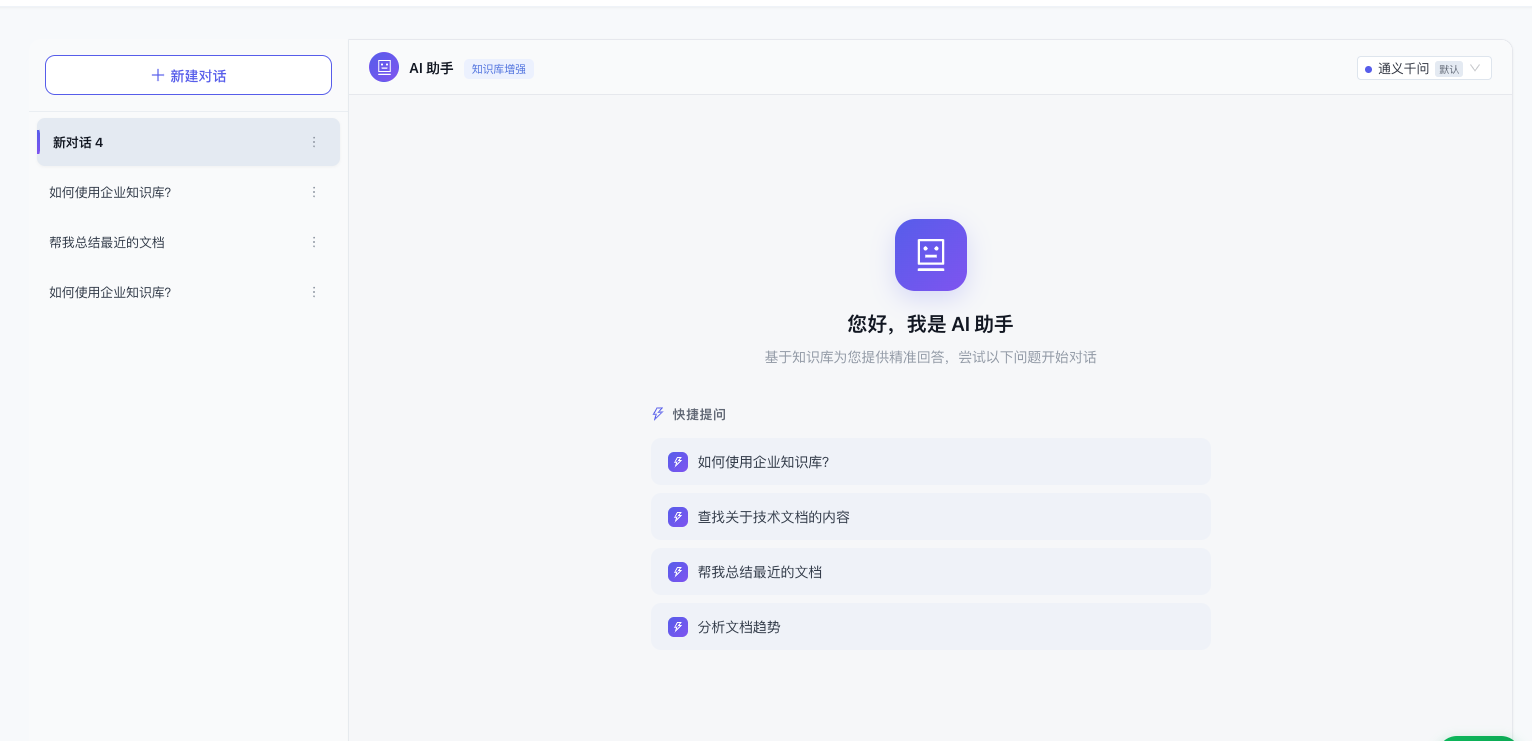
3.4 AI 智能助手(这是最硬核的部分)
这不是调个 API 就完事的"ChatGPT 套壳"。
这套系统实现了一整套 RAG + KAG 双引擎架构:
三种对话模式,适应不同场景:
| 模式 | 原理 | 适用场景 |
|---|---|---|
| 标准对话 | 直接调用大模型 | 通用问答、闲聊、写作辅助 |
| RAG 对话 | 检索知识库中的相关文档片段,注入 Prompt | "我们公司的支付接口怎么对接?" |
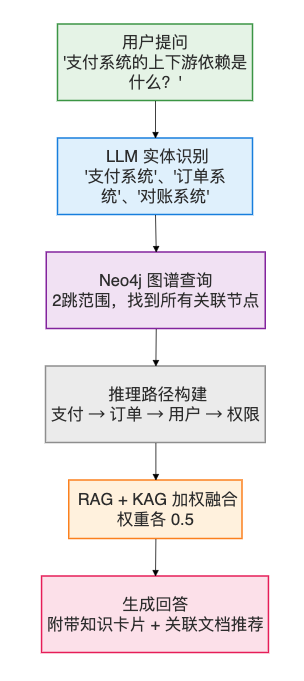
| KAG 对话 | 结合知识图谱中的实体关系,增强上下文 | "支付系统和哪些系统有依赖关系?" |
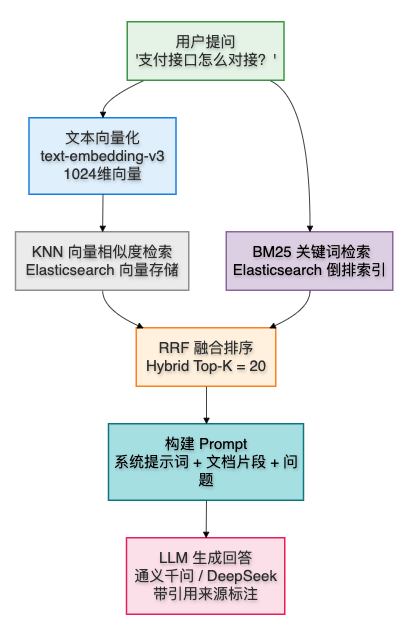
RAG(检索增强生成):
KAG(知识增强生成):
AI 辅助写作:
- 生成文档摘要
- 生成文档大纲
- 内容扩写与润色
- 表达优化
- 自动添加示例
双模型支持:
- 通义千问(qwen3-max):阿里云 DashScope API
- DeepSeek(deepseek-chat):DeepSeek 官方 API
- 可灵活切换,配置即可生效
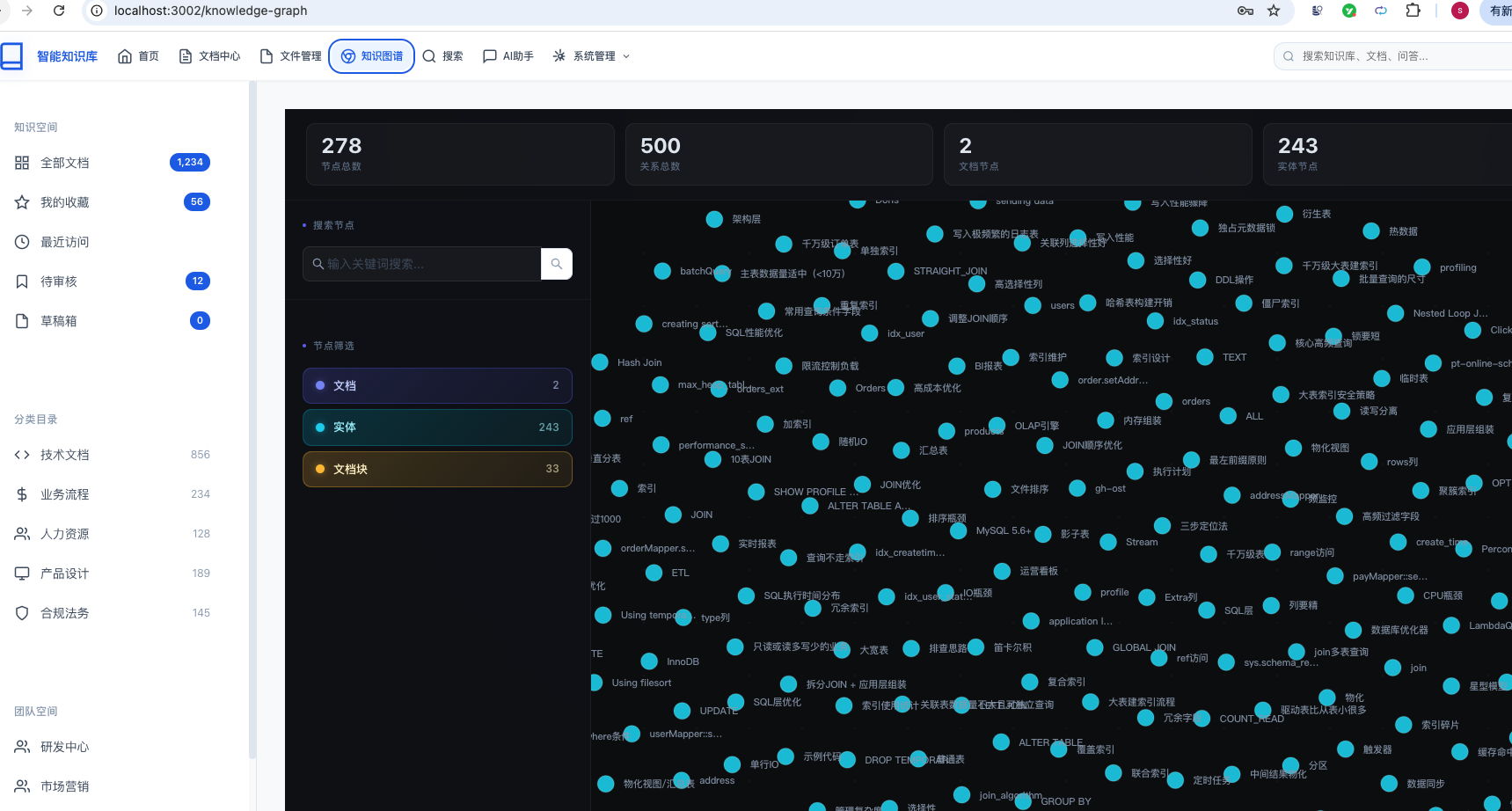
3.5 知识图谱可视化
基于 Neo4j 图数据库构建知识网络,支持:
- 节点管理:按类型(文档/用户/分类/标签)筛选
- 关系查询:按源头/目标类型过滤
- N 度关联:查询任意节点 2-3 跳范围内的关联
- 路径分析:两个知识点之间的最短路径
- 社区发现:标签传播算法,自动识别知识集群
- 前端可视化:ECharts 力导向图渲染,支持节点拖拽、缩放、高亮
3.6 权限管理(真正的企业级 RBAC)
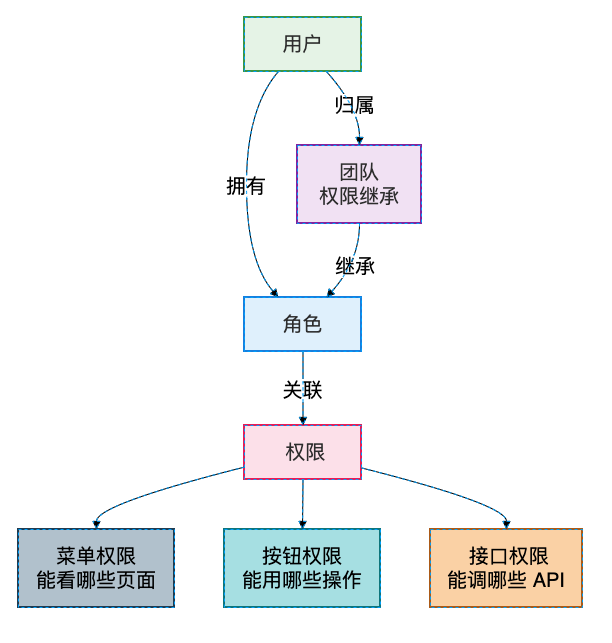
完整功能:
- 用户管理(创建、禁用、删除、重置密码)
- 角色管理(可自定义角色,灵活分配权限)
- 权限树(细粒度控制,精确到每个操作按钮)
- 团队管理(部门/项目组织形式,权限继承)
- JWT 无状态认证 + Token 自动刷新
- 全操作日志记录(谁在什么时候做了什么)
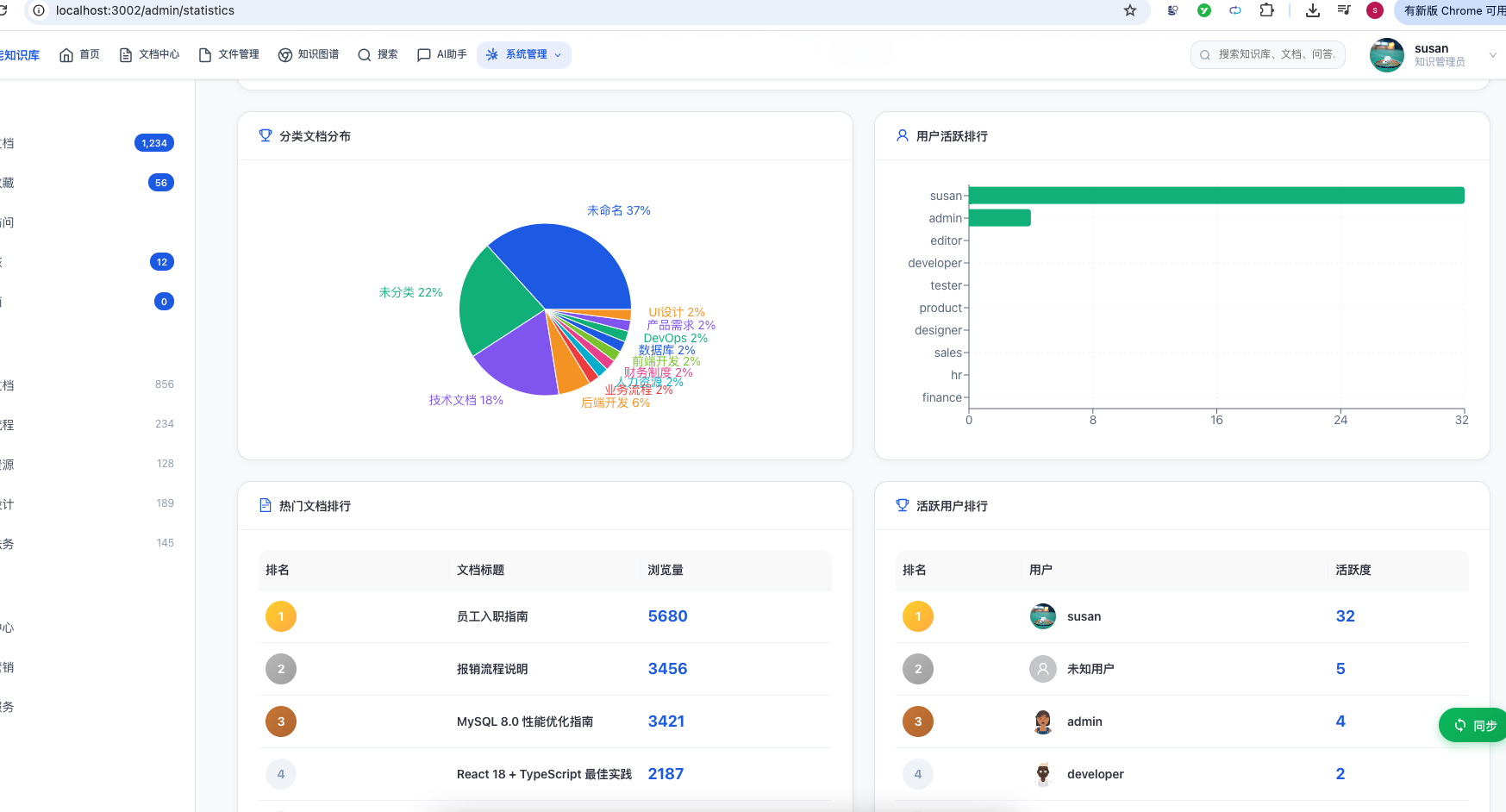
3.7 数据看板 & 统计分析
- 总览仪表盘:文档总数、用户数、今日访问量、AI调用次数
- 文档趋势图:按时间维度的创建/更新趋势
- 用户活跃度排行:谁在贡献、谁在消费知识
- 分类分布图:知识在各领域的分布情况
- 热门文档排行:最受欢迎的技术文档 Top 10
3.8 实时通知系统
- WebSocket 实时推送
- RabbitMQ 异步消息处理
- 通知保留 90 天
- 支持已读/未读状态管理
- 支持管理员群发通知
四、系统展示
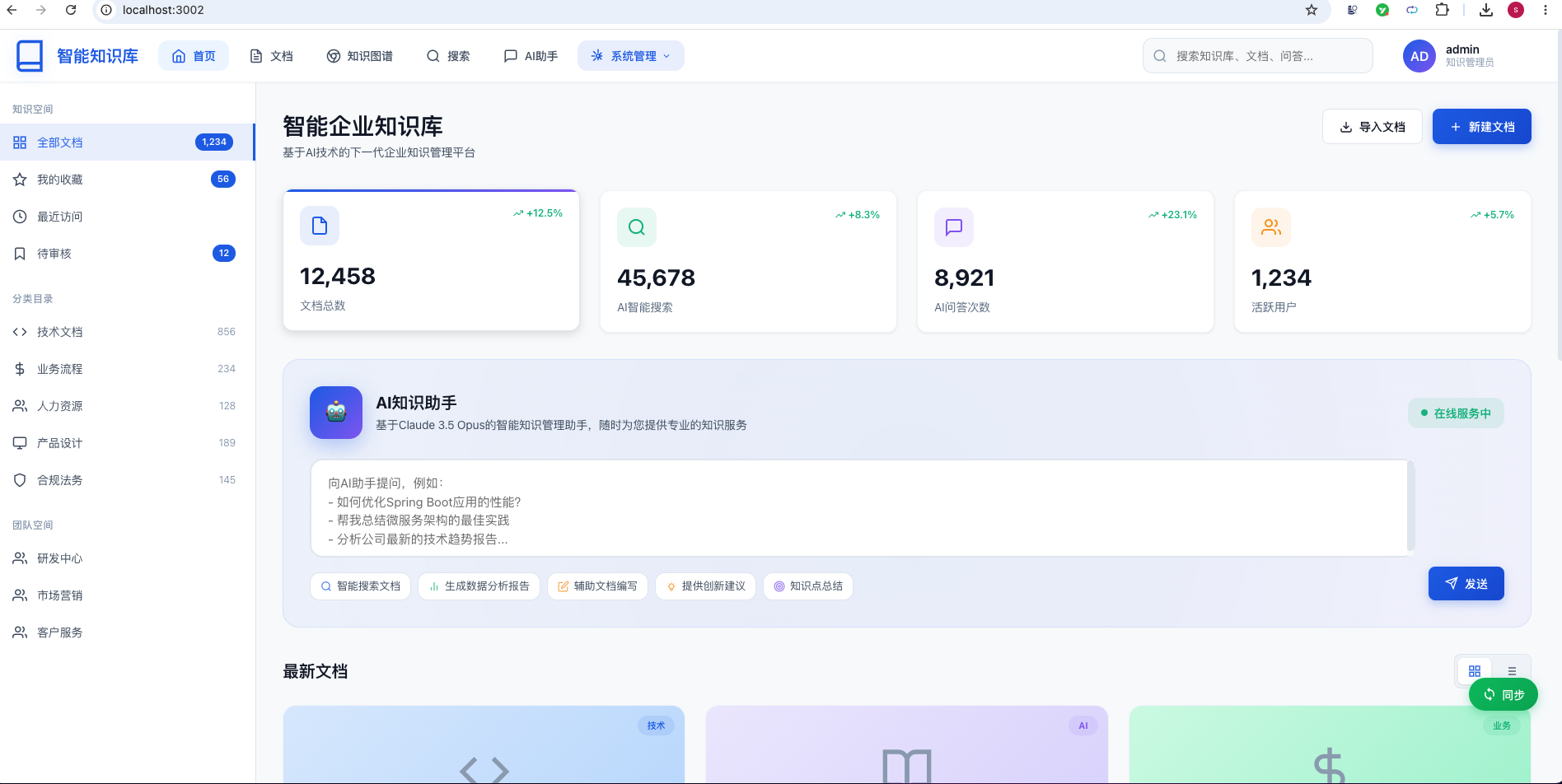
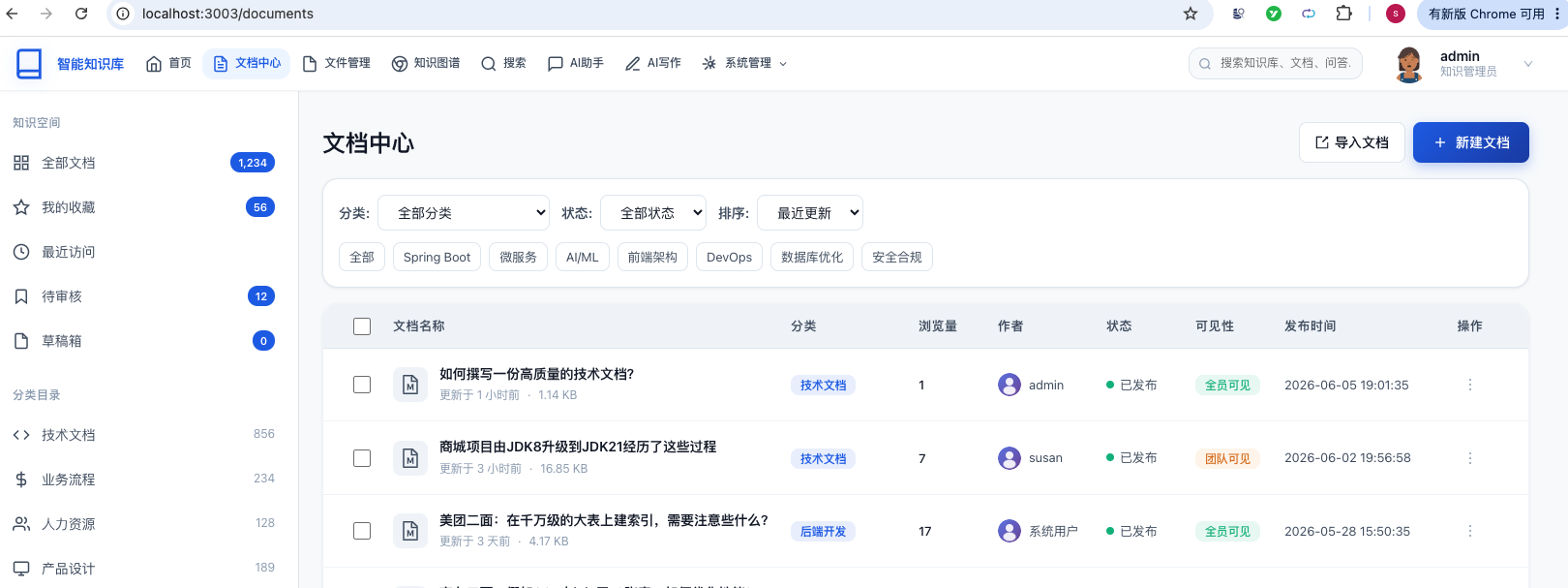
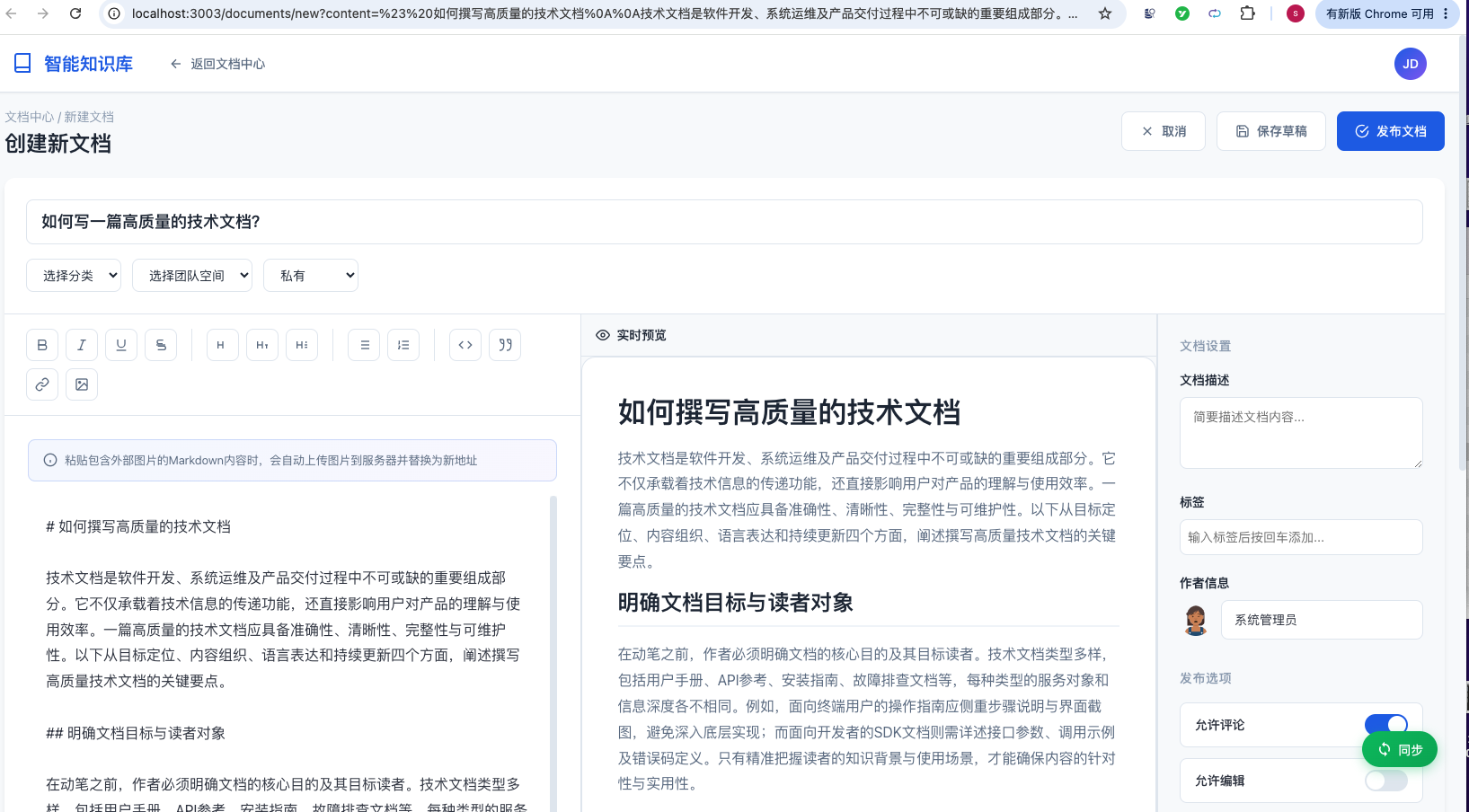
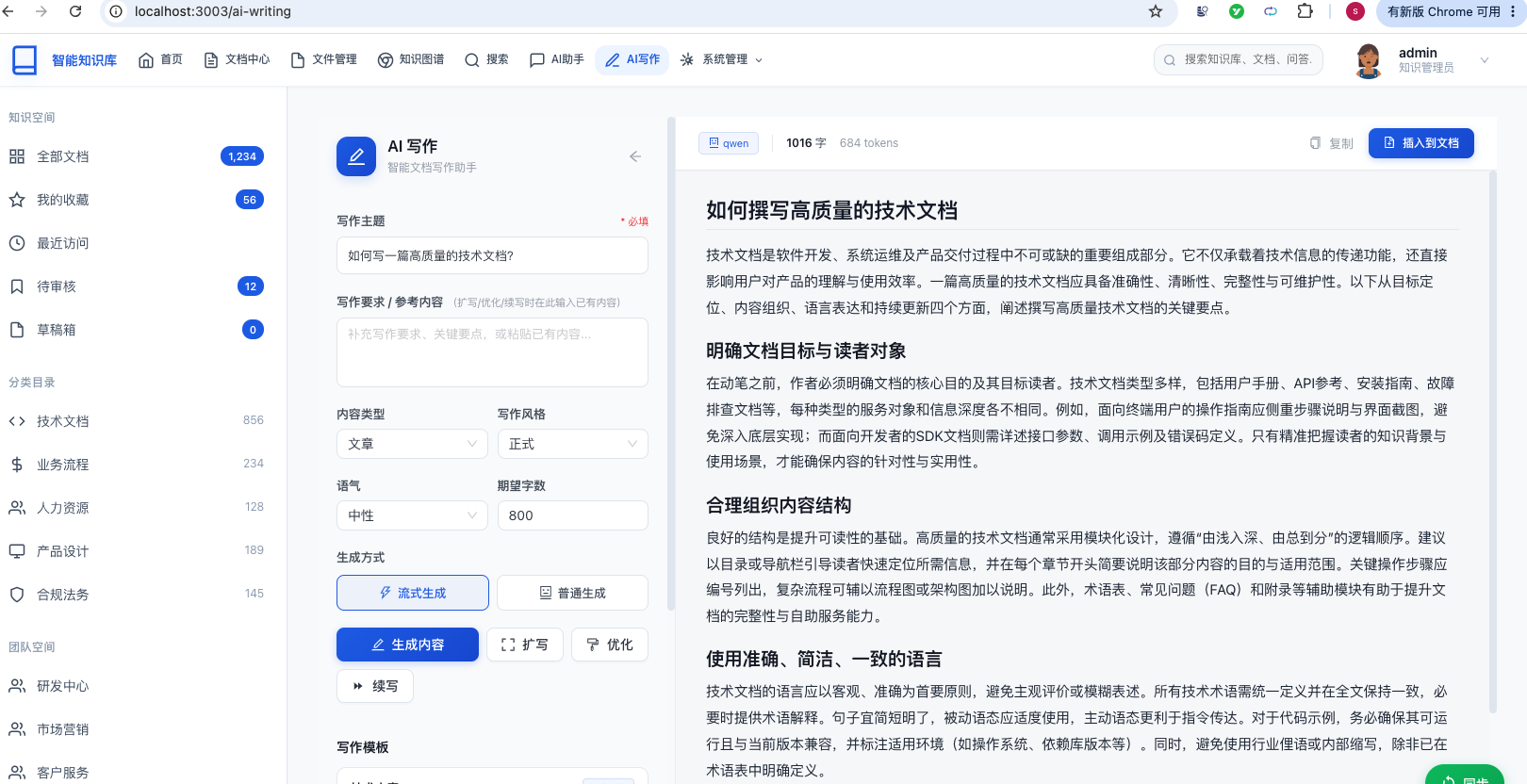
五、项目亮点
5.1 架构亮点
1. 真正的微服务落地,不是"拆模块改个名"
- 10 个微服务独立部署,每个服务有自己的数据库(9 个独立 MySQL 库)
- Nacos 服务注册与发现,服务间通过 Feign 声明式调用
- Spring Cloud Gateway 统一网关,JWT 认证在网关层统一处理
- 有明确的服务边界和调用关系,不是简单的 Maven 多模块
Gateway 的 AuthGlobalFilter 在请求进入时就完成 JWT 校验,提取用户信息后通过 X-User-Id Header 向下游透传。下游服务不再重复处理认证逻辑,只需要从 Header 中读取用户身份即可——关注点分离,代码更清爽。
服务间通信采用 Spring Cloud OpenFeign,用接口+注解的方式定义远程调用,完全不写 HTTP 连接代码。
所有 10 个服务启动后自动注册到 Nacos,支持健康检查、负载均衡、动态上下线。
2. RAG + KAG 双引擎 AI 架构
这不是简单的"接个 ChatGPT API"。
项目实现了一整套可插拔的 AI 引擎架构:
| 维度 | RAG 引擎 | KAG 引擎 |
|---|---|---|
| 数据来源 | 文档内容(向量化分块) | 知识图谱(Neo4j实体关系) |
| 检索方式 | Embedding 向量相似度 + BM25 混合检索 | LLM实体识别 → Neo4j 多跳遍历 |
| 核心优势 | 语义匹配,理解用户意图 | 结构化推理,发现隐含关联 |
| 融合策略 | RRF(Reciprocal Rank Fusion)加权融合,权重可调 |
整个 pipeline 可拆解为独立步骤:文档分块(Chunking)→ 文本嵌入(Embedding)→ 向量索引(KNN)→ 混合检索 → 上下文构造 → LLM 生成。
每一个步骤都有独立的 Service 实现,方便替换或升级。
3. 混合搜索(BM25 + 向量)
不是简单的 ES LIKE 模糊查询,而是实现了搜索结果的多路召回 + 融合排序:
用户搜索 "如何提升系统性能"
├── 路径1: BM25 倒排索引关键词匹配 → 命中"性能优化"文档(精确但可能遗漏同义词)
├── 路径2: text-embedding-v3 向量语义匹配 → 命中"系统调优"文档(语义相近但用词不同)
└── RRF 融合: 对两路结果按倒数排名加权融合,输出 Top-K=20 最终结果向量 embedding 采用阿里云 text-embedding-v3 模型,1024 维向量存入 Elasticsearch 的 dense_vector 字段,支持 KNN 近似最近邻检索。
用户每次搜索异步写入 MySQL,定时任务聚合计算热词排行。
搜索历史支持个人维度管理(查看/清空/导出),热词排行面向全系统展示——既保护个人隐私,又提供全局趋势洞察。
4. RabbitMQ 驱动的事件异步处理
大量耗时操作通过 RabbitMQ 异步解耦,让核心流程保持快速响应:
| 事件 | 生产者 | 消费者 | 说明 |
|---|---|---|---|
| 操作日志 | AOP切面 | kb-foundation | 不阻塞业务请求 |
| 文档索引更新 | kb-document | kb-search/Consumer | 文档发布后异步更新 ES |
| RAG 向量化 | kb-document | kb-ai/ReindexConsumer | 文档发布后异步向量嵌入 |
| KAG 图谱构建 | kb-document | kb-ai/KAGReindexConsumer | 文档发布后异步构建图谱 |
| 视频转码 | kb-file | kb-file/TranscodeConsumer | 大文件转码不阻塞上传 |
| 通知推送 | 各服务 | kb-foundation | 消息异步分发 |
5. 全格式文件预览体系
涵盖 PDF、DOCX、XLSX、PPT、Markdown、TXT、图片、视频(HLS)、音频,用户不需要下载文件就能看到内容。
项目覆盖了企业日常能接触到的几乎所有文件格式,且不需要用户安装任何软件:
| 类别 | 支持格式 | 预览技术 | 关键库 |
|---|---|---|---|
| 分页渲染,支持缩放 | react-pdf 10.x | ||
| Word | .doc/.docx | HTML 实时转换 | mammoth.js |
| Excel | .xls/.xlsx | 交互式数据表格 | SheetJS (xlsx) |
| PPT | .ppt/.pptx | 幻灯片逐页预览 | 后端图片提取 |
| Markdown | .md | GFM 渲染 + 代码高亮 | react-markdown + PrismJS |
| 纯文本 | .txt | 等宽字体渲染 | 原生 |
| 图片 | png/jpg/gif/bmp/svg/webp | 缩略图 + 原图预览 | 原生 |
| 视频 | mp4/avi/mov/mkv/webm | HLS 自适应码率流播放 | FFmpeg + HTML5 Video |
| 音频 | mp3/wav/flac/aac/ogg | HTML5 音频播放 | 原生 Audio |
| 压缩包 | zip/rar/7z | 文件列表展示 | - |
视频上传后自动完成:SHA-256 完整性校验 → FFprobe 提取元数据(时长/分辨率/码率)→ 用户点击"转码"→ RabbitMQ 异步发送转码消息 → FFmpeg 生成 360p + 720p 多码率分片 → HLS .m3u8 播放列表 → 前端根据网络状况自动切换清晰度。
整个流程全异步、不阻塞用户操作,转码进度可通过 API 查询。
导入支持:Word (.docx) → Markdown, Markdown (.md) → 系统文档, 纯文本 (.txt) → 系统文档, 拖拽批量导入
导出支持:Markdown → PDF, Markdown → Word, Markdown → 原格式下载
构建了完整的文档格式转换 pipeline,知识进得来也出得去。
5.2 工程亮点
| 分类 | 亮点数 | 核心关键词 |
|---|---|---|
| 微服务架构 | 4 | 数据库-per-服务、Gateway鉴权透传、Feign声明式调用、Nacos注册配置 |
| AI/LLM | 5 | RAG+KAG双引擎、LLM自动构建知识图谱、SSE流式输出、双模型切换、反馈闭环 |
| 搜索技术 | 2 | BM25+向量混合检索+RRF融合、异步热词分析 |
| 权限安全 | 4 | 三层RBAC、Token刷新请求队列、防全表更新拦截器、AOP注解审计 |
| 存储文件 | 3 | 全格式预览矩阵、HLS自适应流媒体、SHA-256秒传去重 |
| 数据工程 | 4 | Snowflake分布式ID、逻辑删除审计、RabbitMQ事件驱动、定时统计 |
| 前端工程 | 4 | Axios拦截体系、Zustand持久化、路由懒加载守卫、TS零错误 |
| 运维工程 | 4 | 全局异常处理、Knife4j在线文档、虚拟线程 |
5.3 这套源码能带给你什么?
如果你是一个初中级后端开发:
- 微服务怎么拆、怎么做服务发现、怎么写 Feign 接口,这项目里全有
- JWT + RBAC 权限模型怎么设计,代码怎么写,直接看
kb-user-auth - MyBatis Plus 的高级用法(分页、连表、动态 SQL、逻辑删除)
- Elasticsearch 全文检索 + 向量搜索怎么实际落地
- RabbitMQ 异步消息怎么在真实的业务场景里用
- AOP 切面编程实现操作日志和限流
如果你是一个前端开发:
- React 18 + TypeScript 5 企业级项目怎么组织目录和代码
- Zustand 状态管理 + persist 持久化的最佳实践
- Axios 拦截器、Token 刷新、请求重试队列的完整方案
- Ant Design 5 的深度定制(自定义主题、国际化)
- ECharts 在 React 中怎么封装和使用
- 文件上传(大文件分片)、文件预览(PDF/DOCX/XLSX/MD)怎么实现
如果你关注 AI / LLM:
- RAG 完整 pipeline 的代码实现(从文档分块到向量检索到 LLM 生成)
- KAG 完整 pipeline 的代码实现(从实体抽取到图谱构建到融合检索)
- Elasticsearch 向量存储的方案设计和落地
- Neo4j 知识图谱如何由 LLM 驱动自动构建
- 多模型(Qwen + DeepSeek)切换的架构设计
- LangChain4j 在实际 Spring Boot 项目中的集成方式
如果你是架构师或技术 Leader:
- 微服务怎么拆,每个服务的边界如何定义
- 9 个数据库的设计理由、ER 关系、索引策略
- 7 种中间件的选型理由和使用场景
六、企业智能知识库系统常见问题
6.1 企业智能知识库系统和传统知识库系统有什么区别?
传统知识库系统通常只解决“文档存储”和“权限查看”问题,而这套企业智能知识库系统进一步解决了企业知识管理里的三个核心难点:
- 文档多但不好找,所以需要 Elasticsearch 全文检索 + 向量检索 + RRF 融合排序
- 文档能搜到但不好用,所以需要 AI 智能问答、摘要生成、写作辅助和知识推荐
- 知识有关联但看不见,所以需要 Neo4j 知识图谱和 KAG 多跳关系推理
也就是说,它不是传统文档系统的简单升级版,而是一套真正面向 AI 知识管理场景的企业级知识库系统。
6.2 这套企业知识库系统为什么适合写进简历?
因为它同时覆盖了后端、前端、搜索、AI、中间件和工程化治理几个面试高频方向:
- 后端可以讲 Spring Boot、Spring Cloud、JWT、RBAC、RabbitMQ、MyBatis Plus
- 搜索可以讲 Elasticsearch 全文检索、向量检索、热词统计、搜索建议
- AI 可以讲 RAG、KAG、Embedding、LangChain4j、双模型切换
- 数据层可以讲 MySQL、MongoDB、Neo4j、Redis 的分工设计
- 前端可以讲 React、TypeScript、权限路由、文件预览和可视化
相比普通 CRUD 项目,这种企业智能知识库系统更容易体现候选人的系统设计能力和工程落地能力。
6.3 这套 AI 知识库项目适合哪些人学习?
如果你属于下面几类人,这个项目会比较合适:
- 想补一个有深度的企业级项目,用于简历包装和面试表达
- 想系统学习 RAG、知识图谱、AI 问答在业务系统里的落地方式
- 想知道企业知识库系统、权限审批系统、搜索系统如何组合在一起
- 想同时提升后端工程能力、前端协作能力和 AI 项目理解能力
不管你是校招、实习、社招,还是已经工作一两年准备涨薪跳槽,这类项目都比较容易在面试里讲出层次感。
6.4 搜索引擎通常会把这篇文章识别成什么主题?
从页面标题、描述、关键词、目录结构和正文内容来看,这篇文章会更容易被识别为以下主题:
- 企业智能知识库系统介绍
- 企业知识库系统设计与实现
- AI 知识库项目实战
- RAG + KAG + 知识图谱项目
- Spring Cloud 微服务 + React 企业级项目
这样做的目的,是让百度、必应、Google 这类搜索引擎更容易理解页面主题,匹配到更准确的搜索词。