1.100万QPS短链系统介绍:Redis Cluster + ShardingSphere + BloomFilter + Sentinel,把“链接跳转”做成可扩展的高可用底座
1.100万QPS短链系统介绍:让“一个链接跳转”具备工程化的确定性
短链系统真正的难点,从来不是“把 URL 变短”,而是把它变成一个长期可用、可观测、可扩容、可治理的基础能力:
- 业务侧要的是:稳定跳转、低延迟、抗热点、可追踪、可运营
- 工程侧要的是:一致性、幂等性、扩容路径、故障隔离、成本可控
这套项目的定位是:把短链从“工具能力”,升级为可复用的高并发跳转底座。
目录
- 前言
- 什么是 URL 短链?
- 短链跳转原理
- 一图看懂:系统架构与关键链路
- 使用技术
- 亮点 1:读路径极致加速:BloomFilter + 多级缓存 + 分片路由
- 亮点 2:写路径幂等一致:分布式锁 + 事务 + 冲突自愈
- 亮点 3:Redis Cluster 工程化:HashTag 保证关联数据同槽
- 亮点 4:分库分表可扩展:ShardingSphere 32 库 × 256 表
- 亮点 5:稳定性与可观测:Sentinel + 监控告警 + 日志字段化
- 亮点 6:分层布隆:本地时间片 + Redis 时间片(抗穿透与抗扫描)
- 亮点 7:布隆可回收:时间分片 + 定时清理(解决只增不减)
- 亮点 8:跨节点一致:Redis Stream 广播同步本地状态(布隆/本地缓存)
- 亮点 9:广播不翻车:Stream 水位监控 + trim 清理策略
- 亮点 10:时钟同步:Redis TIME 多节点采样 + RTT/2 + 中位数
- 亮点 11:雪花回拨治理:分级处理 + 备用时间源保证单调
- 亮点 12:机器 ID 自动分配:分布式锁 + 心跳续租 + 退出释放
- 亮点 13:访问计数最终一致:Redis 原子计数 + 阈值回写 DB
- 亮点 14:Redis 批量性能:按槽位分组 + RBatch 并发聚合
- 亮点 15:绕过分片中间层:原生数据源池精确查询(稳定兜底)
- 亮点 16:可观测 Debug API:Bloom/生成器状态一键自证
- 亮点 17:本地缓存工程化:KeyGenerator + safe 包装避免空 key/自调用失效
- 亮点 18:跳转稳定性模板:Sentinel + 301 + Cache-Control(边缘友好)
- 亮点 19:Redis 槽位计算:CRC16 + HashTag 提取(对齐集群一致性)
- 亮点 20:多重哈希策略:降低 URL 哈希冲突概率(工程可控)
- 亮点 21:告警闭环:Prometheus + Alert Rules(可运营的 SLO 信号)
- 亮点 22:日志工程化:JSON 结构化 + MDC 关联 + 异步落盘/Logstash
- 亮点 23:短码生成工程:动态长度 + maxValue 缓存 + 序列溢出控制
- 亮点 24:锁治理:统一 tryLock 封装 + 告警风暴抑制
- 亮点 25:冲突自愈:预检 + 唯一约束 + 清理上下文重查合并
- 用户的反馈
- 结语:为什么这套系统容易被面试官喜欢?
- 如何加入星球?
前言
前几天,我在星球中发起了一个星球新项目的投票,目前排名前二的是:复杂AI项目和高并发短链系统。
咱们先把高并发短链系统做了,因为这个项目在面试找工作的时候,非常收到面试官的喜欢。
这个新项目会使用目前业界最新的技术,比如:JDK21、SpringBoot3.5.3等。
短链系统并发量非常高,会使用分库分表、缓存、熔断、限流、布隆过滤器、负载均衡、集群等很多高并发的技术。
1. 什么是 URL 短链?
URL 短链,就是把原来较长的网址,转换成比较短的网址。
我们可以在短信和微博里可以经常看到短链的身影。
如下图,我随便找了某一天躺在我短信收件箱里的短信。
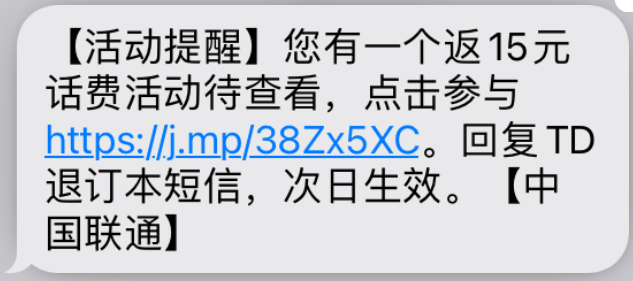
上图所示短信中,https://j.mp/38Zx5XC,就是一条短链。用户点击蓝色的短链,就可以在浏览器中看到它对应的原网址:

那么为什么要做这样的转换呢?来看看短链带来的好处:
在微博,Twitter 这些限制字数的应用中,短链带来的好处不言而喻: 网址短、美观、便于发布、传播,可以写更多有意义的文字;
在短信中,如果含长网址的短信内容超过 70 字,就会被拆成两条发送,而用短链则可能一条短信就搞定,如果短信量大也可以省下不少钱;
我们平常看到的二维码,本质上也是一串 URL,如果是长链,对应的二维码会密密麻麻,扫码的时候机器很难识别,而短链则不存在这个问题;
处于安全考虑,不想让有意图的人看到原始网址。
2. 短链跳转原理
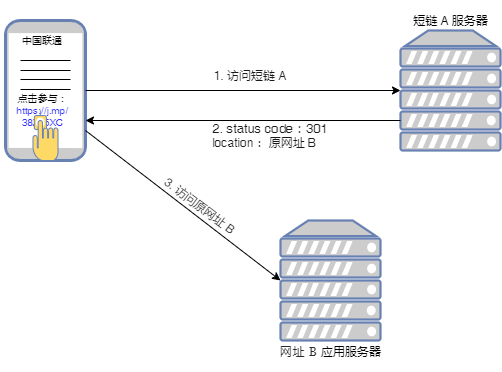
客户端(或浏览器)请求短链:https://j.mp/38Zx5XC
短链服务器收到请求后,返回 status code: 301 或 302,说明需要跳转,同时也通过 location 字段告知客户端:你要访问的其实是下面这个长网址:https://activity.icoolread.com/act7/212/duanxin/index
客户端收到短链服务器的应答后,再去访问长网址:
https://activity.icoolread.com/act7/212/duanxin/index
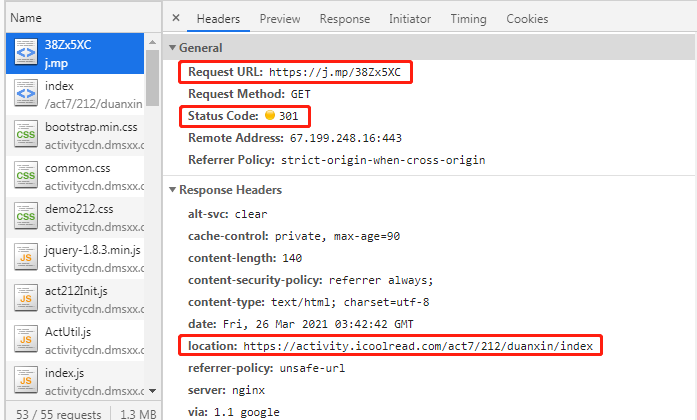
实际浏览器中的网络请求如下图:
一图看懂:系统架构与关键链路
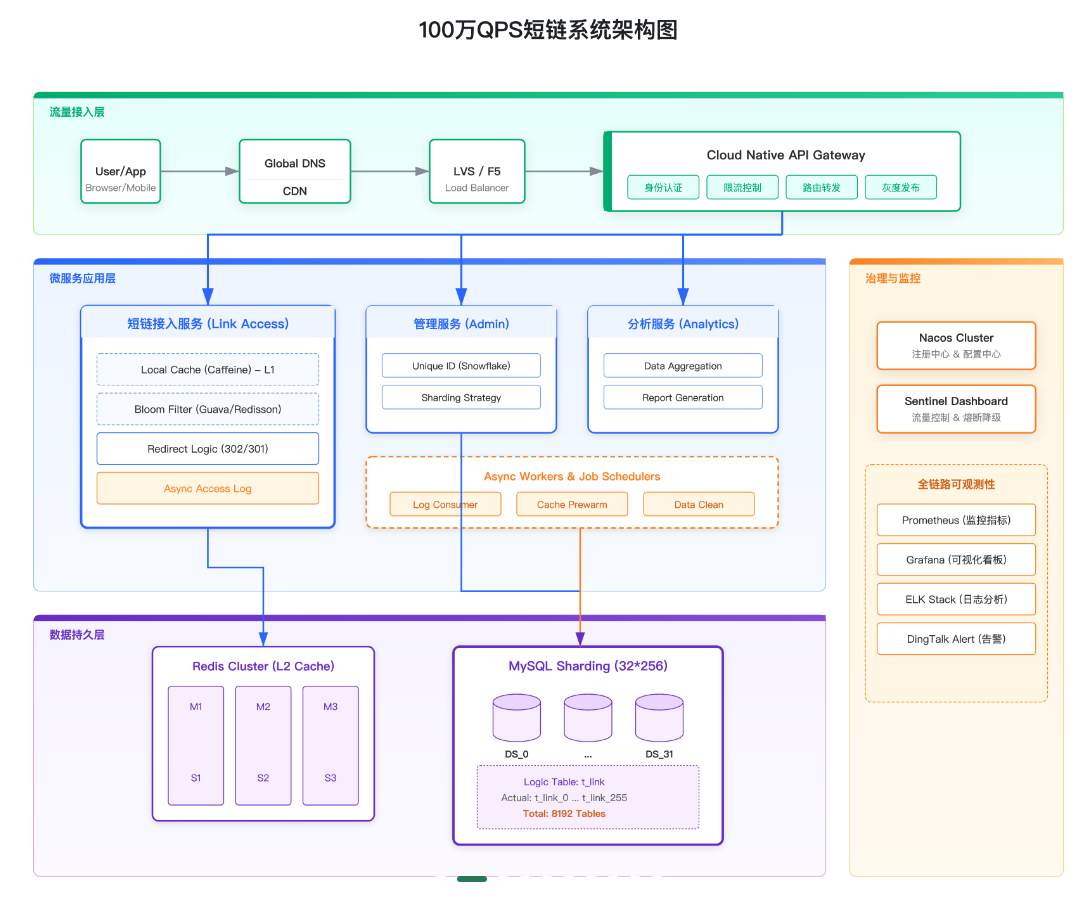
工程上最关键的三件事:
- 读路径:先 Bloom,再 Cache,再 DB,尽量让“跳转”不打数据库
- 写路径:同 URL 串行化 + 事务落库 + 回填缓存,保证幂等与一致
- 扩展性:DB 分库分表、Redis Cluster 分片、无状态服务水平扩容
使用技术
- 语言与框架:Java 21、Spring Boot、Spring Web、Spring Data JPA、Spring Cache
- 数据与分片:MySQL、ShardingSphere-JDBC
- 缓存与中间件:Redis、Redis Cluster、Redisson、Redis Stream
- 稳定性:Sentinel
- 可观测:Micrometer、Prometheus、Alertmanager、Logback、Logstash
- 工程化:Maven、Docker Compose、JUnit 5、Mockito
亮点 1:读路径极致加速:BloomFilter + 多级缓存 + 分片路由
短链解析的主战场是读。你要的是“高命中”和“低抖动”,而不是一堆复杂逻辑。
读路径的工程模板可以总结为一句话:先筛再取,先快再慢。

读路径的关键代码骨架可以抽象成下面这样:
public ShortUrlMapping resolveShortUrl(String shortCode) {
if (!tieredBloomFilterService.mightContain(shortCode)) {
return null;
}
ShortUrlMapping cached = clusterAwareCacheService.getFromCache(shortCode);
if (cached != null) {
return cached;
}
ShortUrlMapping dbMapping = shortUrlDao.findByShortCode(shortCode).orElse(null);
if (dbMapping != null) {
clusterAwareCacheService.putToCache(shortCode, dbMapping);
}
return dbMapping;
}这里最关键的不是“查到了什么”,而是查找顺序:
- 先过 BloomFilter,快速挡掉不存在的 shortCode,避免无意义打库
- 再查 Redis / 本地缓存,把绝大多数读请求拦在缓存层
- 最后才按 shortCode 路由到分库分表查询,并把结果回填缓存,形成后续高命中
这段代码对应的核心能力,分别可以在后文的 TieredBloomFilterService、ClusterAwareCacheService 和 ShortUrlDao 中看到。
你不需要“每次都查库确认”,BloomFilter 让系统具备了更强的抗扫描与抗击穿能力。
亮点 2:写路径幂等一致:分布式锁 + 事务 + 冲突自愈
短链创建的难点不是写入,而是:同一个 URL 在高并发下是否会被重复创建、缓存是否一致、以及异常情况下能否自愈。
写路径关键逻辑在 ShortUrlService.java 的 createShortUrl,这里截取核心骨架:
// 第一层防护:智能缓存检查(支持多重哈希)
CacheCheckResult cacheCheckResult = smartCacheCheck(request.getOriginUrl(), urlHashes);
if (cacheCheckResult.getCreateShortUrlResponse() != null) {
return cacheCheckResult.getCreateShortUrlResponse();
}
String primaryUrlHash = cacheCheckResult.getCurrentHash();
// 第二层防护:同URL串行化
String lockKey = "create_url:" + primaryUrlHash;
return distributedLockService.executeWithLock(lockKey, () -> {
String cachedShortCode = clusterAwareCacheService.getShortCodeByUrlHash(primaryUrlHash);
if (StringUtils.isNotBlank(cachedShortCode)) {
ShortUrlMapping cachedMapping = clusterAwareCacheService.getFromCache(cachedShortCode);
if (cachedMapping != null && request.getOriginUrl().equals(cachedMapping.getOriginUrl())) {
return buildResponse(cachedMapping);
}
}
final String initialShortCode = shortCodeService.generateByStrategy(request.getOriginUrl());
int v = initialShortCode.hashCode() & 0x7fffffff;
int tableIndex = v % NEW_SHARDING_TABLE_COUNT;
int dbIndex = (v / NEW_SHARDING_TABLE_COUNT) % NEW_SHARDING_DATABASE_COUNT;
ShortUrlMapping mapping =
shortUrlDao.preCheckByShortCode(dbIndex, tableIndex, initialShortCode, primaryUrlHash, request.getOriginUrl())
.orElse(null);
if (mapping != null) {
clusterAwareCacheService.putToCache(mapping.getShortCode(), mapping);
clusterAwareCacheService.putUrlHashMapping(primaryUrlHash, mapping.getShortCode());
return buildResponse(mapping);
}
return transactionTemplate.execute(status -> {
String currentShortCode = initialShortCode;
Optional<ShortUrlMapping> existingByCode = shortUrlDao.findByShortCode(currentShortCode);
if (existingByCode.isPresent()) {
// code 冲突自愈:重试生成
}
// persist + flush + 回填缓存
return buildResponse(shortUrlMapping);
});
});把工程问题翻译成机制就是:
- 缓存命中:极致快,低成本
- 缓存未命中:用分布式锁把幂等边界“压缩到单线程”,避免重复创建
- 落库成功:回填 Bloom + Cache + HashMapping,让后续读“直接命中”
同时,这条链路对“hash 冲突”做了工程化收敛:在预检阶段用 originUrlHash + originUrl 进行二次校验,避免把不同 URL 误认为同一条短链(见 ShortUrlDao.java 的 queryHashUrlWithRawDataSource)。
String sql = "SELECT short_code, origin_url, origin_url_hash, create_time, update_time, " +
"expire_days, access_count, status, creator FROM " + tableName +
" WHERE origin_url_hash = ? AND origin_url = ? LIMIT 1";亮点 3:Redis Cluster 工程化:HashTag 保证关联数据同槽
做 Redis Cluster 最常见的工程坑是:同一个 shortCode 的数据被打散到不同槽位,导致批量操作难做、局部热点难治理、链路定位难对齐。
这个项目用 HashTag 把“同一 shortCode 的一组数据”放在同一个槽位上:URL 映射、访问计数、缓存实体可以一键对齐。
关键代码在 ClusterAwareCacheService.java 的 putUrlHashMapping:
public void putUrlHashMapping(String originUrlHash, String shortCode) {
String key = generateHashTagKey(HASH_MAPPING_KEY, originUrlHash);
RBucket<String> bucket = redissonClient.getBucket(key);
bucket.set(shortCode, DEFAULT_EXPIRE_TIME);
}工程价值在于:
- 数据分布更可控:同类 key 同槽,热点可迁移、可观测
- 批量更高效:批量 get/put 更容易按槽分组做并行
- 定位更确定:同一个请求链路的 Redis 访问有更强的规律性
亮点 4:分库分表可扩展:ShardingSphere 32 库 × 256 表
短链系统的 DB 扩展能力必须“写扩散、读定位”。写扩散靠均匀分片,读定位靠稳定路由。
这里用 ShardingSphere 的 inline 算法,按 shortCode 的高位/低位做库表切分,避免传统 % 规则导致的“库表耦合失衡”。
配置见 sharding.yaml:
shardingAlgorithms:
new-database-hash:
type: INLINE
props:
algorithm-expression: ds_$->{((short_code.hashCode() & 0x7fffffff) >> 8) % 32}
new-table-hash:
type: INLINE
props:
algorithm-expression: short_url_mapping_$->{(short_code.hashCode() & 0x7fffffff) % 256}这类“位切分”的工程意义是:
- 库表解耦:表用低位、库用高位,分布更均匀
- 扩容友好:DB 数增加时,迁移成本可控,可灰度
亮点 5:稳定性与可观测:Sentinel + 监控告警 + 日志字段化
百万 QPS 的系统,最怕的不是“某次失败”,而是“失败后你不知道发生了什么”。
稳定性策略很朴素:
- 入口层限流:保护系统不被打穿
- 应用层流控:热点隔离、降级兜底
- 观测闭环:指标、日志、告警联动,故障可定位可复盘
写路径用 Sentinel 包裹,见 ShortUrlService.java:
@SentinelResource(
value = "createShortUrl",
blockHandler = "createShortUrlBlockHandler",
fallback = "createShortUrlFallback"
)
public CreateShortUrlResponse createShortUrl(CreateShortUrlRequest request) { ... }并且用 Redisson 做统一分布式锁封装,见 DistributedLockService.java:
boolean acquired = lock.tryLock(waitTime, leaseTime, timeUnit);
if (!acquired) {
throw new RuntimeException("系统繁忙,请稍后重试");
}亮点 6:分层布隆:本地时间片 + Redis 时间片(抗穿透与抗扫描)
这套系统把 BloomFilter 做成“分层结构”,核心价值是:把不存在的请求挡在 DB 之外,把读链路的下限抬到可控区间。
public boolean mightContain(String shortCode) {
if (localBloomFilterService.mightContain(shortCode)) {
return true;
}
for (RBloomFilter<String> slice : redisTimeSlices.values()) {
if (slice.contains(shortCode)) {
return true;
}
}
return false;
}代码见 RedisTimeBasedBloomFilterService.java 的 mightContain,以及对外统一门面 TieredBloomFilterService.java。
亮点 7:布隆可回收:时间分片 + 定时清理(解决只增不减)
短链场景下 BloomFilter 的通病是“只增不减”,容量最终不可控。这里用时间分片把 Bloom 拆成可回收的窗口,定时删除过期切片即可释放空间。
@Scheduled(fixedRate = 300000)
public void cleanupExpiredSlices() {
doCleanupExpiredSlices();
}代码见 RedisTimeBasedBloomFilterService.java 的 cleanupExpiredSlices。
亮点 8:跨节点一致:Redis Stream 广播同步本地状态(布隆/本地缓存)
“本地缓存/本地布隆”能把时延打到极低,但多节点下天然不一致。项目用 Redis Stream 做增量同步,并且每个节点独立消费者组,确保消息真正广播到每个节点消费一次。
布隆同步(每节点独立 group):
groupName = CONSUMER_GROUP_BASE + ":" + nodeId;
redisTemplate.opsForStream().createGroup(STREAM_KEY, groupName);
List<MapRecord<String, Object, Object>> records = redisTemplate.opsForStream()
.read(Consumer.from(groupName, consumerName),
StreamReadOptions.empty().count(10).block(Duration.ofSeconds(2)),
StreamOffset.create(STREAM_KEY, ReadOffset.lastConsumed()));本地缓存同步(PUT/EVICT 事件广播):
case "PUT" -> syncCacheFromRedis(shortCode, sourceNode);
case "EVICT" -> localCacheService.safeEvictFromLocalCache(shortCode);代码见 BloomFilterStreamService.java、LocalCacheStreamService.java,以及本地缓存安全封装 LocalCacheService.java。
亮点 9:广播不翻车:Stream 水位监控 + trim 清理策略
广播机制如果不控水位,最终会把 Redis 变成“事故源”。项目用两个阈值控制:超过 max-length 做紧急清理,否则按窗口做智能 trim。
if (currentLength > maxStreamLength) {
emergencyCleanup();
}
long retainCount = Math.max(minRetainLength, (long) (currentLength * 0.8));
redisTemplate.opsForStream().trim(STREAM_KEY, retainCount);代码见 CacheSyncMonitorService.java。
亮点 10:时钟同步:Redis TIME 多节点采样 + RTT/2 + 中位数
在雪花 ID、过期判断、冷热策略这些“时间敏感”逻辑里,时钟漂移是隐性炸弹。项目用 Redis TIME 做参考时钟,采样多个节点并 RTT/2 补偿,然后取中位数抵抗异常值。
long serverMillis = timeResponse.getSeconds() * 1000L + (timeResponse.getMicroseconds() / 1000L);
long rtt = Math.max(0L, tEnd - tStart);
long adjusted = serverMillis + (rtt / 2L);
java.util.Arrays.sort(samples, 0, sampleCount);
long median = samples[(sampleCount - 1) / 2];代码见 ClockSyncMonitorService.java 的 getRedisTime。
亮点 11:雪花回拨治理:分级处理 + 备用时间源保证单调
这是面试官最爱问也最容易“讲崩”的点:时钟回拨时你到底怎么保证单调性?项目把回拨分级处理,小幅等待追平,中等直接使用 lastTimestamp,严重则切换到备用时间源,并强制 max(referenceTime, lastTimestamp + 1)。
if (timestamp < lastTimestamp) {
long offset = lastTimestamp - timestamp;
if (offset <= CLOCK_BACKWARDS_SMALL_THRESHOLD) {
Thread.sleep(offset << 1);
timestamp = getCurrentTimestamp();
if (timestamp < lastTimestamp) {
timestamp = lastTimestamp;
}
} else if (offset <= CLOCK_BACKWARDS_MEDIUM_THRESHOLD) {
timestamp = lastTimestamp;
} else {
timestamp = getBackupTimestamp();
}
}代码见 ShortCodeGenerator.java,备用时间源见 ClockSyncMonitorService.java 的 getReferenceTime。
亮点 12:机器 ID 自动分配:分布式锁 + 心跳续租 + 退出释放
雪花算法的“全局唯一”前提是 machineId 全局唯一。项目用 Redis Map 做注册表、分布式锁保护分配过程,启动后心跳续租,退出时释放占用,避免一线大厂最怕的“机器号冲突导致全局雪崩”。
machineId = lockService.executeWithLock(MACHINE_ID_LOCK, 10, 30, TimeUnit.SECONDS, () -> {
Set<Long> usedIds = new HashSet<>(machineIdMap.values());
for (long i = 0; i <= MAX_MACHINE_ID; i++) {
if (!usedIds.contains(i)) {
machineIdMap.put(nodeIdentifier, i);
return i;
}
}
throw new RuntimeException("无可用机器ID");
});代码见 MachineIdService.java。
亮点 13:访问计数最终一致:Redis 原子计数 + 阈值回写 DB
访问计数如果每次落库,DB 会成为瓶颈;如果只在 Redis 里加,又会缺少持久化。这里采用折中方案:Redis 原子计数承载写放大,达到阈值(如每 100 次)再回写 DB。
Long count = clusterAwareCacheService.incrementAccessCount(shortCode);
if (count != null && count % 100 == 0) {
updateAccessCountInDatabase(shortCode, count);
}代码见 ShortUrlService.java 的 updateAccessCountAsync 与 updateAccessCountInDatabase。
亮点 14:Redis 批量性能:按槽位分组 + RBatch 并发聚合
Redis Cluster 下批量操作性能抖动的根因是“跨槽位跨节点 IO”。项目按槽位分组后批量执行,再并发聚合结果,稳定批量吞吐。
Map<Integer, List<String>> shardGroups = shortCodes.stream()
.collect(Collectors.groupingBy(code ->
shardingStrategyService.calculateSlot(generateHashTagKey(URL_CACHE_KEY, code))));
RBatch batch = redissonClient.createBatch();
for (String shortCode : entry.getValue()) {
String key = generateHashTagKey(URL_CACHE_KEY, shortCode);
buckets.put(shortCode, batch.getBucket(key));
}
BatchResult<?> batchResult = batch.execute();代码见 ClusterAwareCacheService.java 的 batchGetFromRedisCluster。
亮点 15:绕过分片中间层:原生数据源池精确查询(稳定兜底)
在“预检/冲突合并/精确落库”等场景里,如果你需要确定性地命中某库某表,走分片中间层可能会引入额外路由不确定性。项目提供原生数据源池,按 dbIndex 直连目标库,再拼出表名做精确查询作为兜底。
@Bean("rawDataSourcePool")
public Map<Integer, DataSource> rawDataSourcePool() {
Map<Integer, DataSource> dataSourcePool = new HashMap<>();
for (int i = 0; i < databaseCount; i++) {
DataSource dataSource = createRawDataSource(i);
dataSourcePool.put(i, dataSource);
}
return dataSourcePool;
}对应 DAO 查询(避免 hash 误命中,做二次校验):
String sql = "SELECT short_code, origin_url, origin_url_hash, create_time, update_time, " +
"expire_days, access_count, status, creator FROM " + tableName +
" WHERE origin_url_hash = ? AND origin_url = ? LIMIT 1";代码见 RawDataSourceConfig.java,以及 ShortUrlDao.java 的 queryHashUrlWithRawDataSource。
亮点 16:可观测 Debug API:Bloom/生成器状态一键自证
很多系统讲稳定性,但面试官会追问“怎么验证”。这个项目直接把关键状态做成接口输出:布隆节点信息、节点 ID、生成器状态、时钟漂移等,具备可验证的工程闭环。
布隆状态(节点信息 + nodeId):
@GetMapping("/status")
public Map<String, Object> getStatus() {
return Map.of(
"nodeInfo", tieredBloomFilterService.getNodeInfo(),
"nodeId", streamService.getNodeId()
);
}生成器状态(机器号 + 回拨统计 + 漂移):
result.put("clockInfo", Map.of(
"localTime", localTime,
"referenceTime", referenceTime,
"drift", localTime - referenceTime
));代码见 BloomFilterController.java、MonitorController.java 的 getGeneratorStatus。
亮点 17:本地缓存工程化:KeyGenerator + safe 包装避免空 key/自调用失效
缓存注解的两个经典坑:空 key 与自调用导致注解不生效。项目提供专用 KeyGenerator 强约束 shortCode,并在本地缓存封装层用 AopContext.currentProxy() 保证走代理,同时提供 safePut/safeEvict 做兜底,避免异常影响主流程。
KeyGenerator(拒绝空 shortCode):
@Bean("shortCodeKeyGenerator")
public KeyGenerator shortCodeKeyGenerator() {
return (target, method, params) -> {
if (params == null || params.length == 0) {
throw new IllegalArgumentException("shortCode参数不能为空");
}
String shortCode = params[0].toString();
if (!StringUtils.hasText(shortCode)) {
throw new IllegalArgumentException("shortCode不能为空字符串");
}
return "shortUrl:" + shortCode;
};
}缓存自调用(强制走 AOP 代理):
return ((LocalCacheService) AopContext.currentProxy()).putToLocalCache(shortCode, shortUrlMapping);代码见 CacheConfig.java、LocalCacheService.java 的 safePutToLocalCache。
亮点 18:跳转稳定性模板:Sentinel + 301 + Cache-Control(边缘友好)
短链的核心接口是跳转,必须可限流、可降级、且对 CDN/浏览器友好。项目用 Sentinel 做 block/fallback,并用 301 + Cache-Control 减少边缘回源,提升整体吞吐。
@GetMapping("/{shortCode}")
@SentinelResource(value = "redirectShortUrl", blockHandler = "redirectBlockHandler", fallback = "redirectFallback")
public void redirect(@PathVariable("shortCode") String shortCode, HttpServletResponse response) throws IOException {
response.setStatus(HttpStatus.MOVED_PERMANENTLY.value());
response.setHeader("Location", shortUrlInfo.getOriginUrl());
response.setHeader("Cache-Control", "public, max-age=3600");
}代码见 RedirectController.java。
亮点 19:Redis 槽位计算:CRC16 + HashTag 提取(对齐集群一致性)
很多同学“用了 Redis Cluster”,但说不清 key 为什么落在某个节点。项目内置 CRC16 槽位计算,并支持 {tag} 提取,既能做压测分布统计,也能做线上热点定位。
public int calculateSlot(String key) {
String hashKey = extractHashTag(key);
return crc16(hashKey.getBytes(StandardCharsets.UTF_8)) % 16384;
}代码见 ShardingStrategyService.java 的 calculateSlot。
亮点 20:多重哈希策略:降低 URL 哈希冲突概率(工程可控)
“哈希冲突”不可能被理论上消灭,只能在工程上把概率压到足够低,并且把冲突处理做成确定性流程。项目在创建短链时生成多重候选 hash:主 hash + 备用 hash,并在缓存检查阶段按序尝试,冲突则跳过继续。
List<String> hashes = new ArrayList<>();
hashes.add(DigestUtils.md5(url));
String sha256 = DigestUtils.sha256(url);
hashes.add(sha256.substring(0, 32));
String saltedUrl = url + "_" + System.currentTimeMillis() / 1000;
hashes.add(DigestUtils.md5(saltedUrl));代码见 ShortUrlService.java 的 generateMultipleUrlHashes,以及缓存冲突跳过逻辑 smartCacheCheck。
亮点 21:告警闭环:Prometheus + Alert Rules(可运营的 SLO 信号)
“监控”不是把指标打出来就算完,真正的工程化是把核心指标变成可运营的告警信号:服务可用性、P95 延迟、连接池、GC、QPS 异常等,能直接推导 SLO。
Prometheus 采集(prometheu.yml):
scrape_configs:
- job_name: 'short-link'
metrics_path: '/actuator/prometheus'
scrape_interval: 30s告警规则(alert_rules.yml):
- alert: HighResponseTime
expr: histogram_quantile(0.95, rate(http_server_requests_seconds_bucket[5m])) * 1000 > 1000
for: 2m
labels:
severity: warning代码见 prometheu.yml、alert_rules.yml。
亮点 22:日志工程化:JSON 结构化 + MDC 关联 + 异步落盘/Logstash
高并发系统排障靠“结构化字段 + 关联能力”,而不是纯文本 grep。项目在请求入口写入 MDC(requestId/userId),并在生产环境用 JSON 日志输出到 Logstash,同时异步落盘兜底,既可检索又不拖慢主链路。
入口埋点(AccessLogInterceptor.java):
String requestId = UUID.randomUUID().toString().replace("-", "");
MDC.put("requestId", requestId);
MDC.put("userId", request.getHeader("X-User-Id"));
request.setAttribute("startTime", System.currentTimeMillis());生产 JSON + 异步(logback-spring.xml):
<appender name="ASYNC_LOGSTASH" class="ch.qos.logback.classic.AsyncAppender">
<appender-ref ref="LOGSTASH"/>
<queueSize>1024</queueSize>
<discardingThreshold>0</discardingThreshold>
</appender>代码见 AccessLogInterceptor.java、logback-spring.xml。
亮点 23:短码生成工程:动态长度 + maxValue 缓存 + 序列溢出控制
短码生成最怕“配置一改就出事故”。项目把短码长度做成可配置,并缓存不同长度对应的 Base62 最大值,避免重复计算;同毫秒内序列号溢出时等待下一毫秒,保证单节点高并发下的稳定输出。
if (timestamp == lastTimestamp) {
long seq = sequence.incrementAndGet() & MAX_SEQUENCE;
if (seq == 0) {
timestamp = waitNextMillis(timestamp);
sequence.set(0L);
}
} else {
sequence.set(0L);
}if (currentLength != cachedLength) {
synchronized (this) {
if (currentLength != cachedLength) {
cachedMaxValue = Base62Util.getMaxValue(currentLength);
cachedLength = currentLength;
}
}
}代码见 ShortCodeGenerator.java。
亮点 24:锁治理:统一 tryLock 封装 + 告警风暴抑制
锁的价值不在“加锁”,而在“把不可控变成可控”。项目把锁统一封装为 tryLock(wait, lease),并在时钟漂移告警等场景加锁抑制,避免多实例同时告警导致风暴。
统一封装(DistributedLockService.java):
boolean acquired = lock.tryLock(waitTime, leaseTime, timeUnit);
if (!acquired) {
throw new RuntimeException("系统繁忙,请稍后重试");
}告警抑制(ClockSyncMonitorService.java):
lockService.executeWithLock(CLOCK_ALERT_KEY, 30, 60, TimeUnit.SECONDS, () -> {
log.warn("检测到严重时钟偏移: {}ms", drift);
return null;
});代码见 DistributedLockService.java、ClockSyncMonitorService.java。
亮点 25:冲突自愈:预检 + 唯一约束 + 清理上下文重查合并
真正的幂等不是“相信缓存”,而是在 DB 唯一约束兜底下仍能平滑自愈。项目在 DAO 保存时,先做预检;落库遇到重复键/哈希约束冲突时清理 JPA 上下文,重新精确查询并合并更新,避免并发下出现脏状态或重复写异常扩散。
try {
entityManager.persist(entity);
entityManager.flush();
return entity;
} catch (Exception e) {
if (errorMsg != null && (errorMsg.contains("Duplicate entry") || errorMsg.contains("origin_url_hash"))) {
entityManager.clear();
Optional<ShortUrlMapping> conflictRecord = preCheckByShortCode(dbIndex, tableIndex, shortCode, originUrlHash, originUrl);
if (conflictRecord.isPresent()) {
ShortUrlMapping existing = conflictRecord.get();
existing.setAccessCount(existing.getAccessCount() + 1);
return entityManager.merge(existing);
}
}
throw e;
}代码见 ShortUrlDao.java。
用户的反馈
有多位球友反馈,在简历中加入短链,面试机会一下子多了很多:
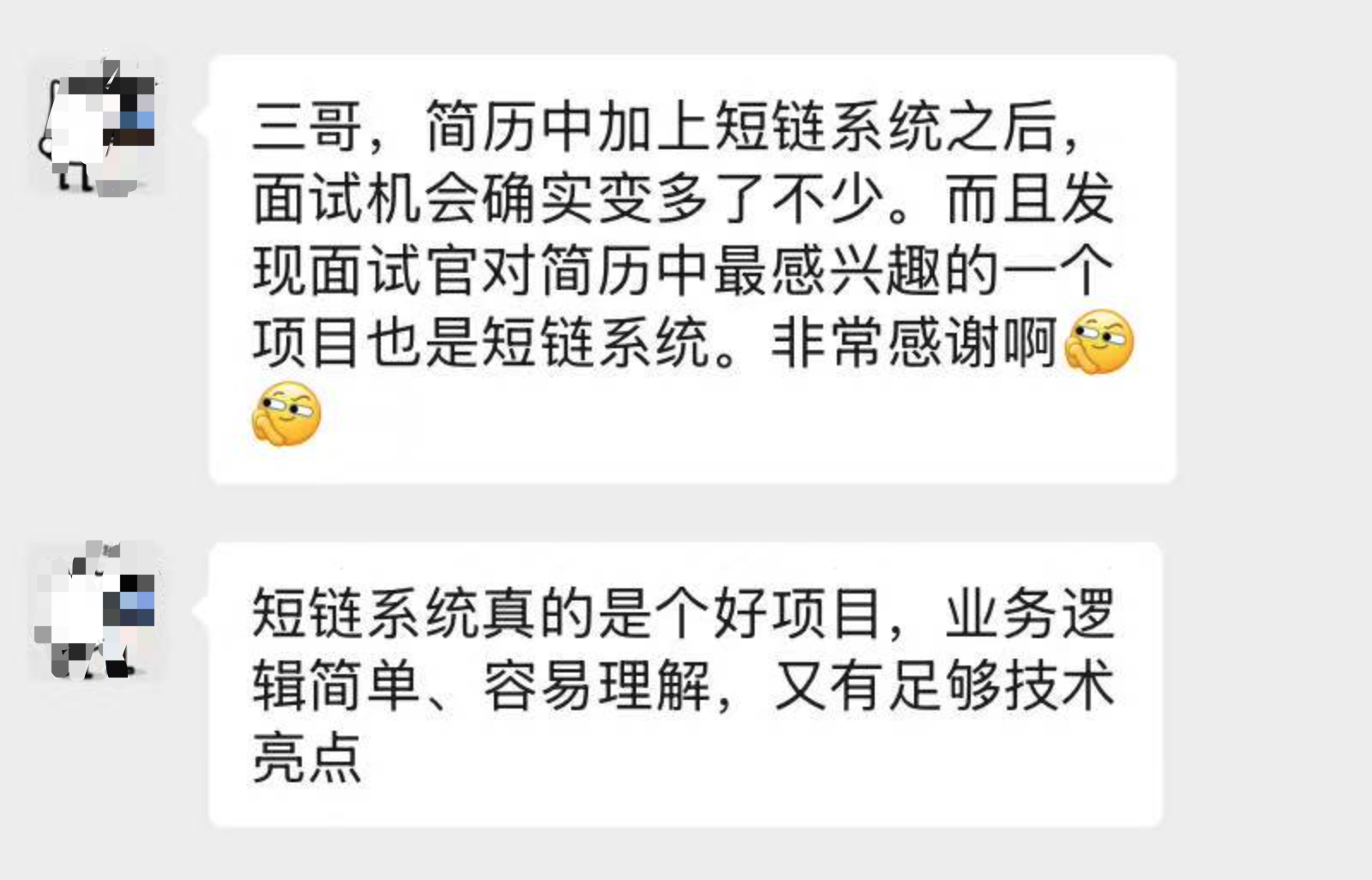

一周拿了三个offer:

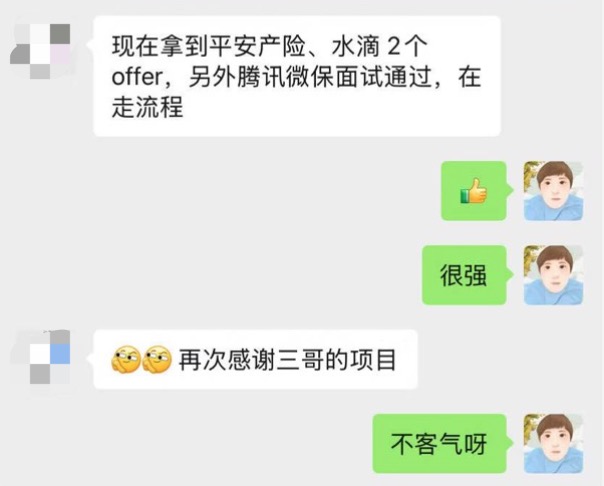
多位球友拿到了不错的offer:

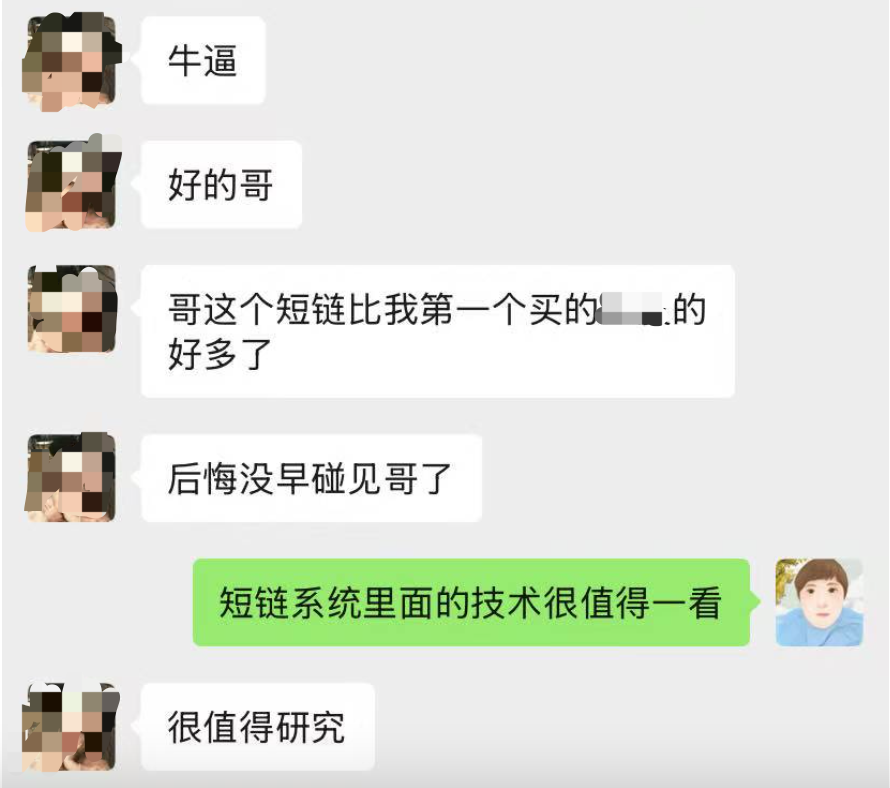
后悔没早点遇到:
结语:为什么这套系统容易被面试官喜欢?
真正容易让面试官眼前一亮的项目,往往不是“功能很多”,而是你能不能把一个看似简单的业务场景,做成有高并发深度、有工程化取舍、有线上稳定性思维的系统。
- 它把“短链跳转”这件事,做成了完整的高并发读写链路:BloomFilter、多级缓存、分库分表、Redis Cluster、限流降级都不是概念,而是能串成闭环的工程方案。
- 它不只讲 happy path,还把热点击穿、缓存失效、哈希冲突、时钟回拨、分片扩容、日志削峰这些真正的线上问题考虑进去了。
- 它把很多面试高频问题都提前准备好了:为什么需要 BloomFilter、为什么要分布式锁、为什么要分库分表、为什么要做多重哈希、为什么要做参数级热点保护。
- 它不是普通 CRUD 项目,而是典型的“大流量基础设施型项目”:越往细节里讲,越能体现候选人的工程能力和架构思维。
- 它既适合校招、实习,也适合社招和晋升,因为你既能拿它讲项目亮点,也能拿它讲系统设计、稳定性治理和性能优化。
这套系统最核心的价值,可以概括成三条主线:高并发读路径(快)、幂等一致写路径(稳)、工程化治理能力(可扩展、可观测、可运维)。它不是“把短链接做出来”,而是把短链做成一个能扛流量、能讲深度、能拉开差距的系统。
如何加入星球?
如果你想要的不只是“看懂文章里的亮点”,而是直接拿到完整源码、开发教程、答疑支持和项目包装思路,那么加入 Java突击队 星球会更直接。
100万QPS 短链系统只是其中一个代表性项目,真正的价值是:你可以同时获取多个实战项目、技术专题和求职支持,把项目经验、面试表达和简历竞争力一起补齐。